![]()
“Quantopian inspires talented people everywhere to write investment algorithms”
The Opportunity
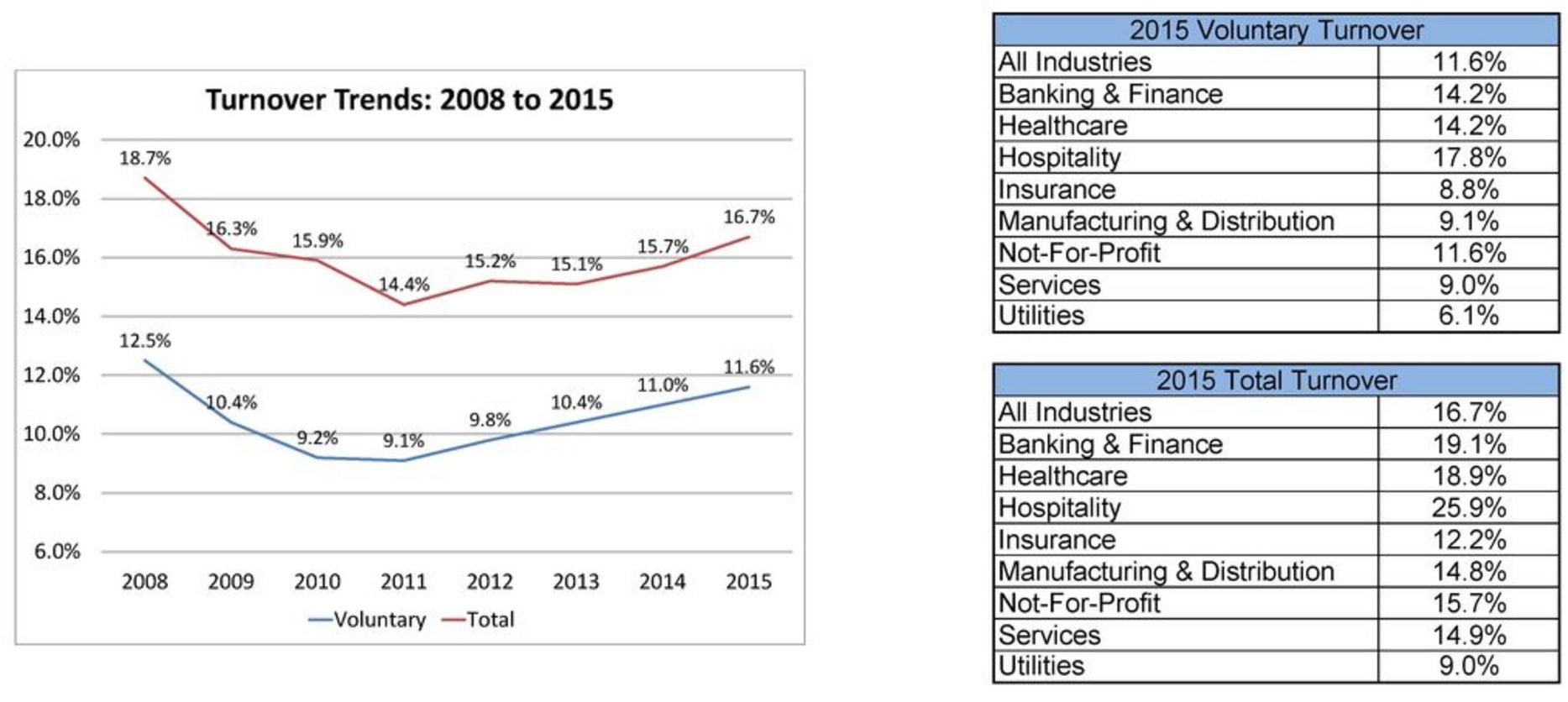
Quantitative hedge funds, which instead of human traders use computer algorithms and mathematical models to make investment decisions, are becoming increasingly popular. This is due to the fact that their performance has been much better than that of traditional hedge funds.
As more investment managers seek to implement quantitative strategies, finding people has become a great challenges as many people with the requisite skills to develop trading algorithms have little interest in working for a big, established hedge funds.

Solution
Quantopian, a crowd-sourced quantitative investing firm, solves this issue by allowing people to develop algorithms as a side-job.
On one hand, the company provides access to a large US Equities dataset, a research environment, and a development platform to community members, which are mainly data scientists, mathematicians and programmers, enabling them to write their own investment algorithms.
On the other, Quantopian acts as an investment management firm, allocating money from individuals and institutions to the community top-performing algorithms. The allocation is based on the results of each algorithm backtesting and live track record.
If an algorithm receives an allocation, the algorithm developer earns 10% of the net profit over the allocated capital.
Effectiveness and Commercial Promise
On the algorithm developer side, Quantopian’s community currently has over 100,000 members including finance professionals, scientists, developers, and students from more than 180 countries from around the world.
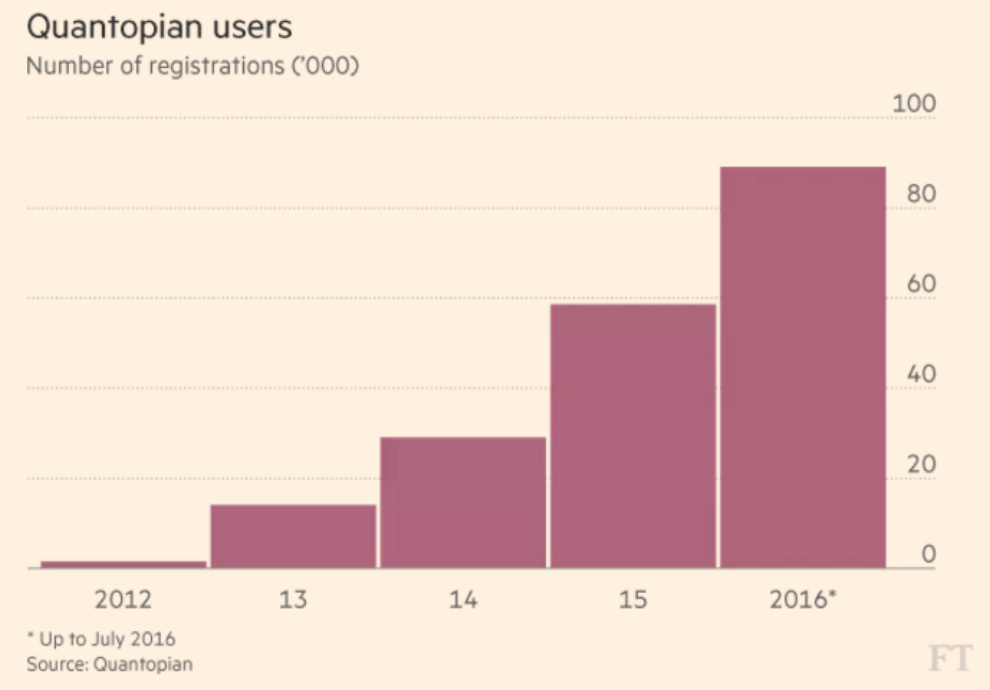
Members collaborate with each other through forums and in person at regional meetups, workshops, and QuantCon, Quantopian’s flagship annual event.
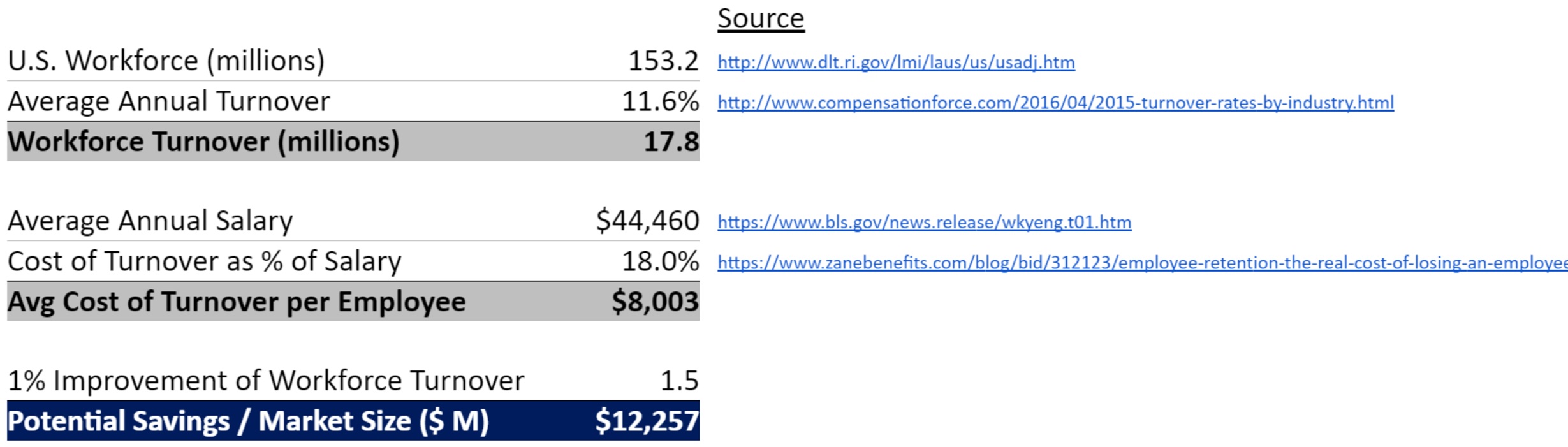
On the fundraising side, last year Steven Cohen, one of the hedge fund world’s biggest names, promised up to $250m of his own money to the platform. Moreover, they started managing investor capital last month. The initial allocations ranged from $100k to $3m with a median of $1.5m per algorithm. By the end of 2017, the expect allocations to average $5m-10m per algorithm.
Concerns
Trading algorithms sometimes converge on buy or sell signals which can generate systemic events. For example in August 2007 all quant algorithms executed sell orders at the same time. During two weeks quant trading strategies created chaos in the financial markets.
If an event similar to August 2007 occurs again, it might harm Quantopian returns if the algorithms in which money is allocated converge.
Quantopian can mitigate this risk by regularly analyzing their exposition to particular stocks and the overlap between the different strategies they managed and their portfolio with the portfolios of other quant managers that disclose their positions.
Alterations
We believe that Quantopian approach can be utilized for any “market” that requires accurate predictions. Therefore, Quantopian model can be exported to other markets such as weather prediction, in which users are paid by weather forecasting agencies, or sports results, in which users are paid by sport betting sites, or for public policy solutions as part of open government initiatives.
Sources:
- https://www.ft.com/content/b88e6830-1969-11e7-9c35-0dd2cb31823a
- https://www.quantopian.com/about
- https://www.quantopian.com/faq
- https://www.quantopian.com/home
- https://www.ft.com/content/0a706330-5f28-11e6-ae3f-77baadeb1c93
- https://www.novus.com/blog/rise-quant-hedge-funds/
- http://www.wired.co.uk/article/trading-places-the-rise-of-the-diy-hedge-fund
Team members:
Alex Sukhareva
Lijie Ding
Fernando Gutierrez
J. Adrian Sánchez
Alan Totah
Alfredo Achondo