A smart marketplace for smarter travelers
Problem/Opportunity
According to Bond Brand Loyalty, there is $100 billion worth of unclaimed loyalty points. According to another loyalty research firm, Colloquy, about $48 billion worth of loyalty points and rewards are earned each year, of which approximately 33% will never be redeemed.
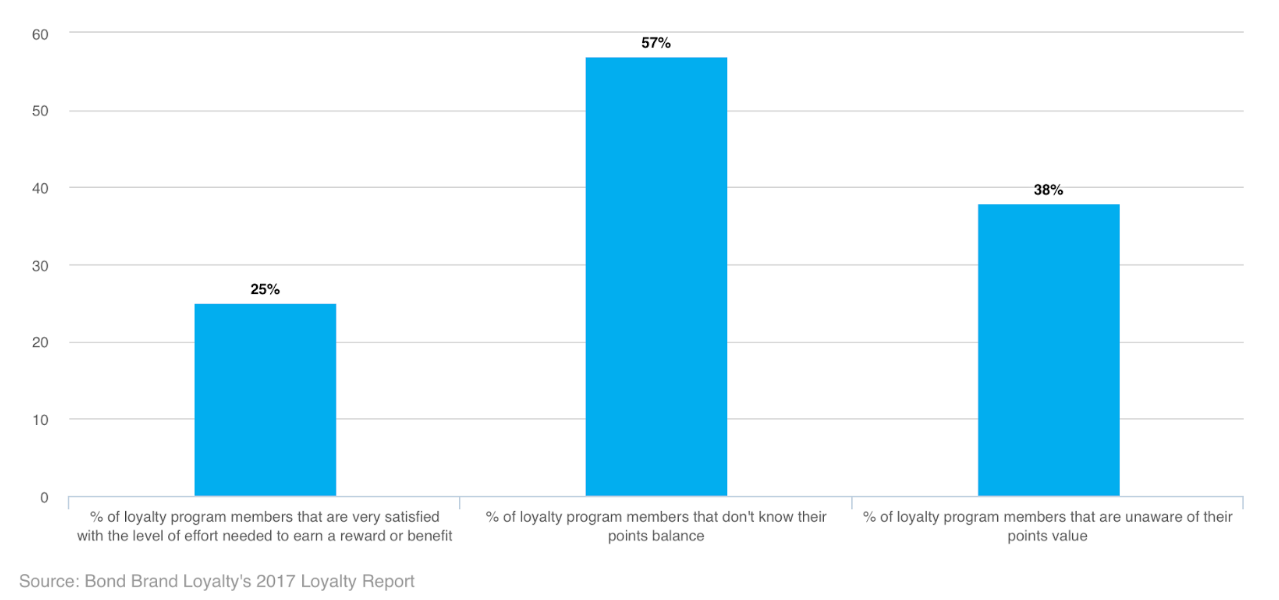
Many customers are unaware of their points balance or what their points can purchase. Hence points accumulate and expire, and customers lose incentives to stay loyal to brands. For companies, even though unredeemed points are a large source of frequent flyer program profits, research shows that customers who redeem points are more likely to display greater engagement and work harder to earn the next reward. A positive redemption experience can drive members to continue to spend with a brand.
While some customers might be interested in transferring their points or redeeming them on behalf of others, there is currently an institutional void borne out of what economists refer to as the hold-up problem and a lack of trust between any buyers and sellers.
Solution
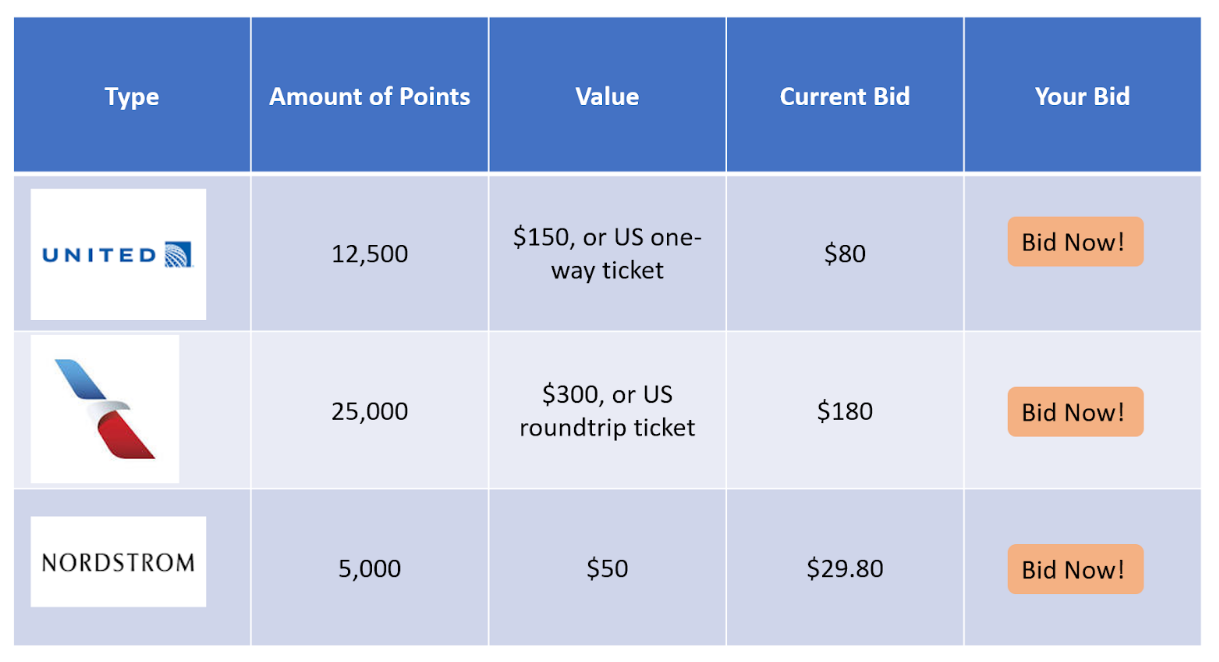
To fix the problem of unused points balances, we create a two-sided marketplace where “sellers” can post how many points they have for which program, and “buyers” can bid on the points they want. Once the auction closes to the highest bidder, funds will be held by the platform in escrow, and the seller will then utilize the points according to the buyer’s wishes (ex: United flight from NY to SF). Upon the buyer’s receipt, funds will flow to the seller.
In this first iteration, we enable sellers to book travel for buyers. Most current loyalty programs do not allow for free transfer of points between individuals; thus, until this program changes, buyers and sellers will need to communicate to ensure that sellers book itineraries correctly. Although there is nothing to prevent customers from doing this already, our platform provides value both by improving discoverability of these opportunities and solving the problem of buyer and seller trust by holding payment in escrow until delivery is verified.
Over time as more loyalty programs enable free transfer of points, our marketplace can accommodate more situations. For example, for sellers with too few points to be of much use, we can allow them to auction their points directly. Buyers can accumulate points from multiple sellers and earn otherwise inaccessible rewards. Eventually, with enough liquidity, our platform can add further value by matching blocks of points to satisfy arbitrary trades, in the same way securities exchanges match bids and asks.
As Point-to-Point grows, it will not only benefit from cross-side network effects, but also open up additional product and business opportunities. As the platform collects data from transactions, we can build a recommendation engine to highlight deals for specific customers. We will also utilize algorithms to educate sellers on points required to cross more valuable thresholds. For example, if a seller had 1489 points with Chase, the algorithm could list shops that the seller would be interested in that could also yield a high return point value, enabling that seller to cross the threshold and sell their 1500+ points for a higher amount. Our platform will also collect relevant data outside the marketplace (ex: new credit card bonuses, 5x points on certain categories, etc.) and distribute this information to members so that they can have a one-stop shop for all loyalty point programs. This will induce stores to participate in our program, as our algorithms can enable higher spending and more efficient advertising.
We intend to monetize through a commission-based revenue model. For trades in which points are paid for in cash, Point-to-Point would collect a 3-5% fee on the transaction amount. For trades in which points from one program provider is exchanged for those of another, Point-to-Point will not collect any commission. This incentivizes more buyers (and therefore, sellers) to use the platform, creating benefit for all.
Pilot/Prototype
Our initial pilot sets up partnerships with loyalty programs that have a wide network of points and already have transfer systems in place, such as Starwood Preferred Guest, Chase Ultimate Rewards, or American Express Membership Rewards. These points can already be redeemed in a variety of settings (hotels, flights, and online retailers) and can sometimes be shared between household members.
We can market Point-to-Point to the popular points forums, including The Points Guy and Reddit, who in general capture a market that is more likely to be motivated by points programs. In line with what Eisenmann, Parker, and Van Alstyne recommend in their article “Strategies for Two-Sided Markets,” we would subsidize early adoption and adoption by price-sensitive users, and work to secure “marquee” users’ exclusive participation with loyalty programs. To incentivize early adopters, we can subsidize transactions for buyers and provide bonuses to sellers.
Furthermore, we will induce further loyalty through discount referrals. To ensure that new entrants do not steal market share, we would form temporary exclusive contracts with participating programs as well as offer our own form of points (earn points to redeem for percent discounts on trades). Over time, we will expand to more loyalty programs, offering an enormous selection for users.
Validation
To ensure our solution meets its objective of creating a liquid market for rewards points while benefiting both points programs and users, we would focus on empirical measures of market liquidity, such as those proposed by Gabrielsen, Marzo, and Zagaglia like liquidity ratio, turnover ratio, and variance ratios. We could also measure the following product success metrics:
- Number of Sign-Ups
- Retention Rates (e.g., 7-day and 28-day return rates, DAU, WAU, MAU)
- Usage Per Member (e.g., # of trades and volume executed)
- # of Referrals
- Increase in Engagement with Loyalty Programs
Competitors
Although loyalty programs have become a differentiating feature, allowing companies to win repeat customers and gain market share, the concept of a secondary market where buyers and sellers are matched based on factors, such as willingness to pay, is still relatively new. Currently, Giift is a loyalty programs and gift card network, allowing consumers to track and exchange points from program issuers (airlines, hotels, retailers, etc.) with one another. However, the “exchange rate” is dictated by Giift (not what the market will bear) and given that only points are exchanging hands, not cash, this limits what a consumer would be able to receive and thus, overall trading activity.
The only other company taking a similar approach of creating a two-sided market platform is Digital Bits. By tokenizing points accumulated with an airline and allowing customers to redeem them for cash or rewards at another rewards provider of their choice, Digital Bits is creating a blockchain-based market and along with it, more flexibility for users. We feel that our solution can successfully compete with Digital Bits because it facilitates communication between buyer and seller without requiring integration with a brand’s existing app or interface. We are also skeptical of the incremental value a blockchain framework provides relative to the additional usage and development complexity it requires. As such, we feel our first-mover advantage and initial user base can perpetuate adoption on both sides of the market.
Sources
https://medium.com/@dfcatch/loyalty-myths-is-breakage-good-873950da26dc
https://www.crunchbase.com/organization/raise-marketplace
https://www.crunchbase.com/organization/cardpool
Eisenmann, Thomas, Geoffrey Parker, and Marshall W. Van Alstyne. “Strategies for two-sided markets.” Harvard Business Review 84, no. 10 (2006): 92.
Gabrielsen, Alexandros, Massimiliano Marzo, and Paolo Zagaglia. “Measuring market liquidity: An introductory survey.” (2011).
Team
Siddhant Dube
Eileen Feng
Nathan Stornetta
Tiffany Ho
Christina Xiong