- Genesis and Overview
Our team initially did a review of Pokemon Go’s success as an augmented reality platform. The game was superimposed over a layout of a real-world location on a user’s cellphone, and would interact through augmented reality. The game was widely popular and one of its unintended side-effects was that it motivated a large number of players to be more physically active. As each of the different goals were in different locations, players had to walk significant distances if they were particularly competitive. While not the primary purpose of the game, it got us thinking that there was definitely an angle to be tapped on.
With the increased adoption of wearables, the cult-like fitness industry is ripe for an AI integration. Tribe is our vision of an adaptive workout platform that combines machine learning and augmented reality. Tribe knows about all your physical attributes, such as height, weight, how much you ate yesterday, how much you slept and even what your fitness goals are. Based on all these, it can propose a workout for you that’s tailored to what your body needs at that very point in time. Each person will have a completely unique interaction with Tribe.
- The Problem
There are a whole range of fitness apps on the market now that attempt to guide users towards individual fitness goals. Most of them are fairly rigid and expect you to follow a set training program without any deviation. The classic couch-to-5k running guide is a clear example of this, where you can’t skip or modify a day’s workouts. Given the rigidity, it’s also not surprising that the attrition rate from these programs are remarkably high.
There are several solutions to the individual who desires varied, customized workouts. seemingly simple solution to the individual that wants a customized, flexible workout, is to hire a personal trainer. However, that is a costly route which wouldn’t work for most people. To figure out how our platform could help, we tried to understand exactly what a personal trainer does, and how it could be replaced by AI. A personal trainer is usually well educated with a substantial background in kinesiology. They’re training style has also evolved based on the number of clients they’ve seen, and their ability to prevent injury before it happens, as well as understanding each client’s limits, and trying to push them farther. In essence, it was a skill that was based on interpretation after being experienced with multiple repetitions – sounds a lot like machine learning.
- The Solution
Enter Tribe, a software based solution that provides the first-ever augmented reality workout. Tribe will leverage a system of virtual gyms similar to Poke gyms with particular workout functions at each gym. This means that as the user base grows, groups will exist at certain gym locations and users will be performing the same exercises simultaneously. While this is not a group workout, there is a social component to it. Members, in a sense, are part of a workout tribe, similar to those that have been popping up around the globe in the social fitness craze of the last decade.
App-based fitness challenges are still virtual. One of the most well known virtual experiences is Fitbit’s “Adventures.” Through adventures, users can take a virtual journey through a wilderness hike, motivating them to reach a step goal. The experience is based on images, and there is no integration with the user’s surrounding environment.

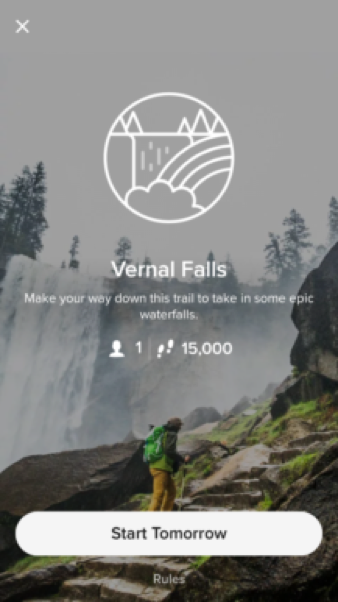
- How it works
Step 1 – Collecting User Data. Users sign up to the platform and integrate it with their existing fitness tracker. For the purpose of this illustration, we’ll assume that Tribe is synced to a Fitbit. The user is then able to confirm the height and weight inputs that are retrieved from Fitbit as well as add their own personal information such as location, workout preferences and any past injuries. Based on all the information provided, Tribe is able to access historical fitness data from the Fitbit (heartrate, step count, workout intensity), and combine this with the workout goals to create a custom workout plan for the user.
Step 2- Location recommendation. When a user wants to have a workout, they can access Tribe and let it know that they’re trying to spend a given time on a workout – 60 min for example. Tribe will then process where you are, as well as the workout you need and give you directions to a workout location. Users will be able to elect from free locations (a public fitness area or an open field), or paid locations (a gym that Tribe has partnered with). The prompt to go to the location will be very similar to that of PokemonGo which engages the user in a game-like environment using augmented reality.
Step 3 – Workout Recommendation. Once you’re at the location, Tribe’s guided workout begins. This is where the platform’s core competency is. Tribe will already have all your data from the current day, and even the day before. It’ll be able to understand that you may have had a long night out with little sleep, or that you haven’t worked out in 4 days and have been sleeping 12 hours a day. Based on this information, as well as your physical attributes and goals, Tribe will be able to propose a workout that’s customized for you at that very point in time.
Step 4 – The Guided Workout. Very much like PokemonGo, Tribe will be able to guide you through your workout through augmented reality. Users will be able to place their phone in a visible place and see objectives on the screen. Perhaps an animated balloon 4 feet off the ground as a target for box jumps, or a cartoon character that holds a 2-minute plank with you. In addition to all this, the use of the front and back facing cameras on the phone will keep users honest by tracking their movements – very much like a more modern, portable version of Dance Dance Revolution.
- Challenges and proposed alterations
One of the challenges for this app is that unlike Pokemon Go, there will need to be workout specific spaces that account for the safety of users. A gym cannot exist in the middle of an intersection, for example. An exercise that requires the user to impact the ground cannot be on concrete.
- Marketing and partnerships
Some obvious marketing opportunities exist, starting with existing gyms and personal trainers. As the workouts could be anywhere, one potential location is existing gyms. Additionally, the trainers at the gym or independent trainers could craft workouts that can be integrated into the app and advertised to its users. Our target customer would already be interested in working out, and therefore our marketing campaigns will be targeted at the places they already are – in addition to gyms, also 5k races, farmers markets, and healthy food stores where athletes looking for more personalized workouts congregate. Lastly, we will use social media, particularly fitness influencers, to gain traction.
- Funding Requirement and Timeline
While we will need $2M to fully develop this technology, we are asking for $200K in funding to get us to a first pilot in one mid-sized city. This will enable us to create the initial exercise programming prototypes, develop the initial software prototype, identify locations within a city for gym activities, and partner with local organizations to gain a following. Once we can prove the model in a single city, we will expand to additional geographies.