Dictionary
RSTI includes an Ugaritic and an Akkadian glossary. We are building these glossaries from the ground up, adding words as we encounter them in the texts.
Properties
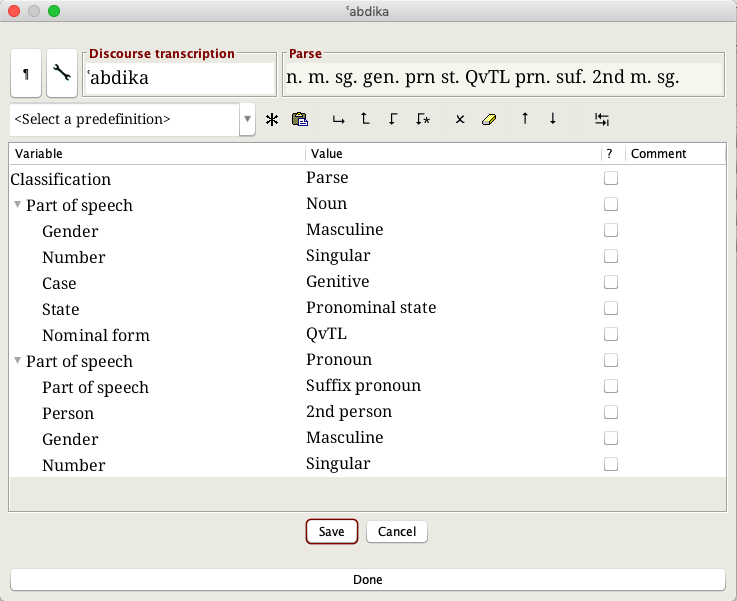
Every word is described by a series of parse properties. The image shows the OCHRE interface where we add properties from an internal controlled vocabulary. These variable-value pairs allow us to query for words based on any combination of parse properties.
OCHRE provides a number of guided workflow wizards that aid in the process of adding words to the glossary and parsing them. In brief, the lexicography wizard walks the user through a text, stopping at each unidentified word. OCHRE searches the glossary to determine if the word is already attested. If not, the wizard guides the user through the process of adding the new word and form.
As we add more words to the dictionary, OCHRE’s intelligence increases. It suggests more possible matches. The whole process becomes faster and faster. Eventually, it becomes possible to allow OCHRE to identify words without human intervention. This is more possible for our syllabic texts, due to the lack of orthographic overlap between grammatical forms. For our alphabetic texts, there will always be a need for a researcher to decide if a word like ʿbdk is singular, genitive, etc.
This guided workflow was designed with intention to approximate the process philologists have followed for decades. We do not intend to replace the careful, reflective, and slow process that still has value in academic research. However, we do wish to reduce the time spent on repetitive tasks. More importantly, we want to emphasize the value of organizing philological data in a semistructured graph database.
RSTI benefits from the work of our graduate student assistants: Colton Siegmund and David Harris. Thank you!