Background – What does the media industry currently look like, how is music selected in public places?
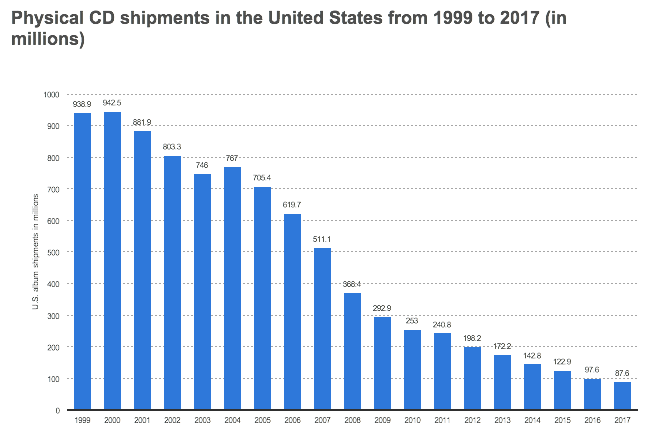
Among the media industry, music is the second most profitable medium worldwide with a 45% digital revenue share (with Games taking the first place with 60%). Moreover, music is completely going digital as the physical CD shipments in the US have decreased from 940 million in 1999 to 88 million in 2017.
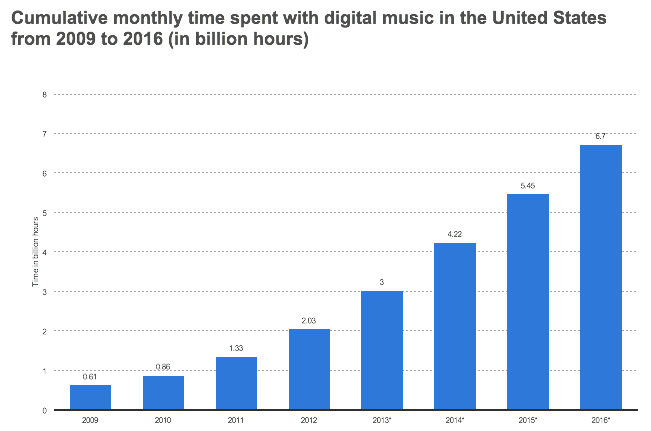
Consumers are not only shifting to digital music, but every year the time consumers spend listening to digital music increases. In less than 10 years the time spent listening to digital music increased approximately in 6 billion hours, and the gap between music streaming and music downloads has also been widening, giving an opportunity to music platforms to implement and improve products that better match / suggest music to consumers in real time.

Today music is selected in the following way:
- B2B: Stores choose the music they play by taking into consideration the season of the year (holidays for example) and the average demographic of its consumers (age, gender, location, among others).
- B2C: At individual parties or reunions, consumers choose the music based on the preferences of the owner of the playlist, device and/or venue. The music is selected based on the assumption that the preference of all the guests is the similar to the preference of the owner.
Opportunity – Where are there pain points in the current system?
There are 3 main pain points in the current way media is selected and played in public spaces:
- No feedback loop: Music and media is often selected and curated by an individual and consumed by a user group in a particular setting with a “best-guess” effort to match audience preferences.
- Impact of music on shopping habits: The current system is not optimized for the shopping habits of the individuals in the store but is based on broader, generalized rules of music selection such as aggressive rock for Sales or classical for perusing.
- Impact of music on bars/ clubs: Bars and nightclubs have disproportionate reliance on good music selection to attract and retain patrons, which is often repetitive or selected in line with staff wishes.
Proposed Solution – How can a AI address those pain-points?
We would hope to use the best practices of recommendation engines and network analysis to generate a group optimum playlist, optimizing on most satisfied customers rather than total social welfare. A playlist would auto-generate based on this predicted best possible sequence of songs and would be provided as an integrated option in traditional music players within the App Stores of Apple or Android. The pipeline steps are displayed below:


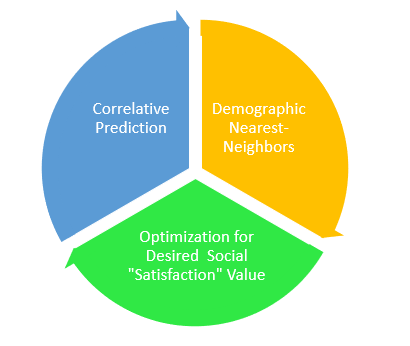
Commercial Promise
In terms of B2B the business model could be based on a subscription model application that companies use to gather information about the music preferences of the customers that visit their stores or that they have in their database. This information would bring value by improving the shopping experience, having the possibility to influence shopping habits and also for marketing purposes. This could be applicable to retail stores, bars and clubs. In terms of the B2C channel the technology could be used to improve the experience in private parties or reunions. In the B2C channel the business model would more based on partnerships with existing music streaming application to help them improve the service they offer.
Benefits/Challenges
Benefits: Immediate feedback loop in public places to create a more personalized experience for consumers, collection and analysis of data based on music choice effectiveness for various seasons/locations/events/demographics
Challenges: Issues identifying causation vs. correlation for level of music influence, potential negative public perception of using music to influence consumer feelings and actions, difficulty of introducing brand new music with little or no related data points
Potential Competition
The key players in the music streaming industry have the capability to develop a viable product, with music personalization being a key push in recent years. Spotify is the market leader in terms of its influential playlist selections.Rivals such as Pandora, Google Play Music and Apple Music are also investing in personalization of music services.
In the startup space, Muru is a company targeting the B2B space. It offers background music streaming services for venues, allowing the venue to create a music template that will keep playing the full duration that venue is open and the playlist will also evolve on the fly.
Sources
http://www.sciencemag.org/news/2015/07/background-music-may-influence-your-spending-habits
https://www.psychologistworld.com/behavior/ambient-music-retail-psychological-arousal-customers
https://www-statista-com.proxy.uchicago.edu/study/14059/digital-music-in-the-us-statista-dossier/
https://techcrunch.com/2018/04/20/musiio/
https://thenextweb.com/contributors/2017/07/20/muru-music/




{kind=link}