A thoughtful smart monitor for personalized health over time
Problem
Currently, there is no easy way for people to receive a holistic picture of their daily health. There are Fitbits that can track steps and calories burned, at-home monitors that check blood pressure, and thermometers to check body temperature. Besides the yearly checkup with a primary care physician, however, there are very few ways to gain access to a detailed report about our health. Continuous monitoring of a patient’s health is crucial for both preventative care and management of chronic conditions; however, tests that require people to go out of their way to produce samples (ex: the traditional pee-in-a-cup method and daily diabetic blood glucose testing) are cumbersome at best and often very painful, costly, inconvenient, and difficult to scale. Furthermore, for many of these patients with chronic conditions, there are significant challenges in encouraging adherence to medical regimens, which only exacerbates the aforementioned problems.
The diagnostic and medical labs industry currently has annual revenues of $53 billion. Of that, it’s estimated that $8.5 billion is spent annually on urine testing and screening. Additionally, according to one medical study, the average diabetes patient spends nearly $800 per year on supplies for testing their blood glucose levels, and about $2,100 more on insulin prescriptions and associated supplies. Based on the American Diabetes Association’s most recent estimates, 23.1 million Americans have been diagnosed with diabetes, and there are approximately $327 billion spent on diabetes treatment each year. While diabetes represents just one diagnostic case, these numbers point to tremendous upside and opportunity for a new, disruptive solution to make patients’ lives easier and at a more affordable price.
Solution + Value Prop
Our solution, Dr. Loo, uses IoT sensors, cloud-hosted big data analytics, and machine learning algorithms to give customers dramatically enhanced insight into their current and future health by leveraging day-to-day urine data. While long-term growth and success in this area may require advances in diagnostic technology, there are a number of compelling use cases that are already feasible which we can use to develop our products, while we continue to perform the research and development necessary to achieve our long-term ambitions.
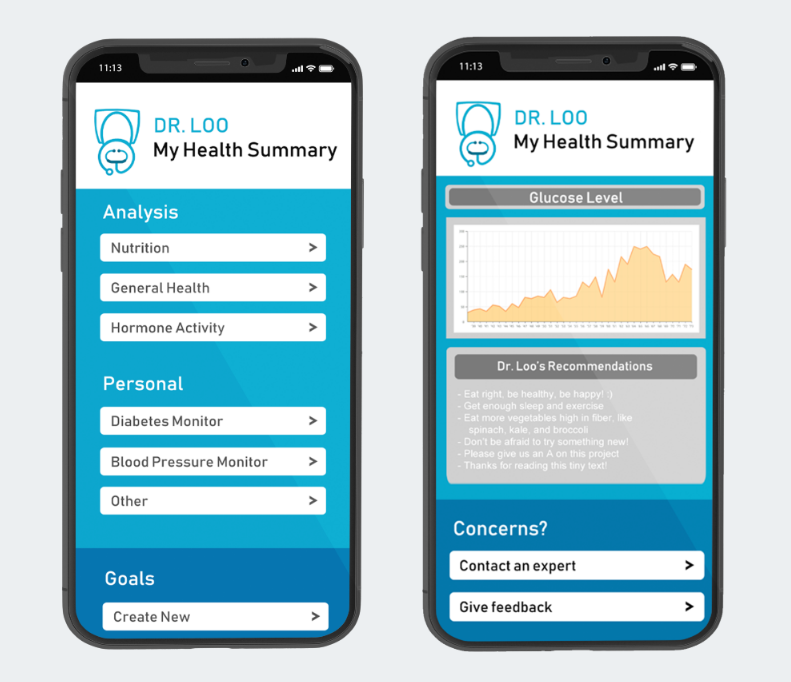
Our MVP is an add-on cartridge to toilets, which will collect samples of users’ urine to monitor their health. These smart toilet cartridges will contain urinalysis test strips with numerous chemical pads (each representing a different test, outlined below, and changing colors when reacting to compounds present in urine) and an optical camera that will capture the results on these strips. Additionally, a smell sensor connected using IoT will be incorporated into the product to provide even more robust results using the odor of a person’s urine. These results will then be digitized, analyzed, and sent in a daily summary to a user’s downloaded app on their phone.
The strips, optical camera, and smell sensors will incorporate machine learning technologies by feeding the outcomes through the database to come up with a final analysis for the customer based on careful interpretation of colored chemical pads and smell inputs. This will be available to the customer through an app on their mobile device. Additionally, we will anonymize the collected data and run algorithms on verified data from patients with preexisting conditions to assist in the diagnosis of other customers. This incorporation of crowd-sourcing will enable our solution to become even more accurate as more customers use our product.
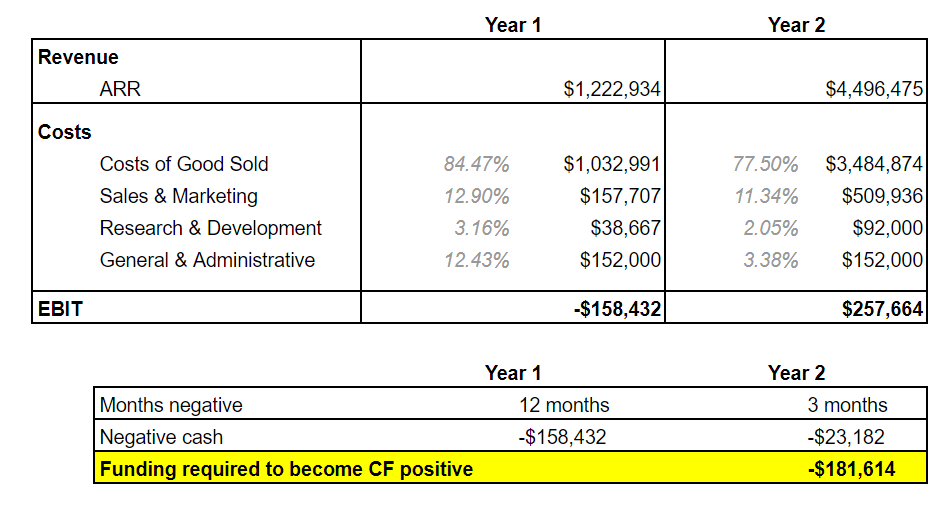
Samples of a Mock-Up for Our Prototype


While dipsticks for urinalysis have been on the market for decades, the accuracy of those results are heavily dependent on proper sample preparation, correct interpretation of the color scales, and precise readout timing. Our product presents two valuable propositions: a) the testing process requires little to no change in users’ daily behavior, and b) the strips themselves can contain dozens of different tests, customized based on the users’ health needs.
Specifically, we would like to measure the following types of metrics:
- Nutrition. Urinalyses can identify a person’s nutritional deficiencies by determining whether a person is under or over the daily recommended range of intake on certain vitamins, fats, sugar, protein, etc.
- Metabolic Analysis (yeast/fungal, vitamin and cellular energy markers)
- Amino Acid Levels & Oxidative Stress Analysis
- Hormone Activity. Urinalyses that detect surges in LH (luteinizing hormone) or the presence of hCG (human chorionic gonadotropin hormone) can help women who want to become mothers: (1) plan for their pregnancy by predicting time of ovulation and peak fertility and (2) confirm their pregnancy.
- LH Hormone Ovulation Test
- hCG Pregnancy Test
- General Health. Urinalysis can be indicative of a person’s overall health. In addition to ensuring a person is well hydrated through the color and cloudiness of the urine, dipstick tests can measure acidity, the presence of blood and specific gravity.
- pH level. Whereas more acidic urine (i.e. lower pH levels) can be associated with stress, inflammation, dehydration and a high-carb diet, a more alkaline urine pH in the range of 5 to 7 is indicative of “calmer physiology, hormone balance, as well as safer and more successful fat loss”. Higher urine acidity can also hint at acidosis, a condition that can lead to kidney stones or be indicative of existing kidney diseases.
- Urinary specific gravity (concentration of solutes in urine; provides information on kidney’s ability to concentrate urine).
- Presence of Red & White Blood Cells.
- Disease-Specific Risks.
- Glucose level (for diabetics)
- Protein level (for kidney disease)
- Presence of bacteria (for urinary tract infections)
- Prostate cancer
In addition to diagnostic capabilities, our product can serve a therapeutic objective by syncing results and making them available to a patient’s doctor. For instance, patients with diabetes would find it particularly beneficial to ensure their blood glucose levels are within normal range and be prompted of appropriate times during the day to take insulin shots. Dr. Loo is also convenient, enabling patients who previously had to go through the discomfort of pricking their finger to simply monitoring their glucose levels through a normal, painless activity. Similarly, certain illnesses require a patient to keep the pH of their urine within specific margins to ensure the efficacy of treatment.
Based on the intended metrics and capabilities described above, we’ve identified two target customer segments:
- Users who have no existing conditions or physical symptoms. These users are typically in the 25-40 age group and are very health-conscious. They may have a family history of diabetes, high cholesterol and/or other illnesses, and thus are interested in more frequent monitoring of their personal health.
- Users with existing conditions. These users are typically in the 41+ age group and as patients of diabetes, kidney disease and/or other conditions, they need to ensure that certain metrics, such as blood glucose level and urine pH, are within a specific range.
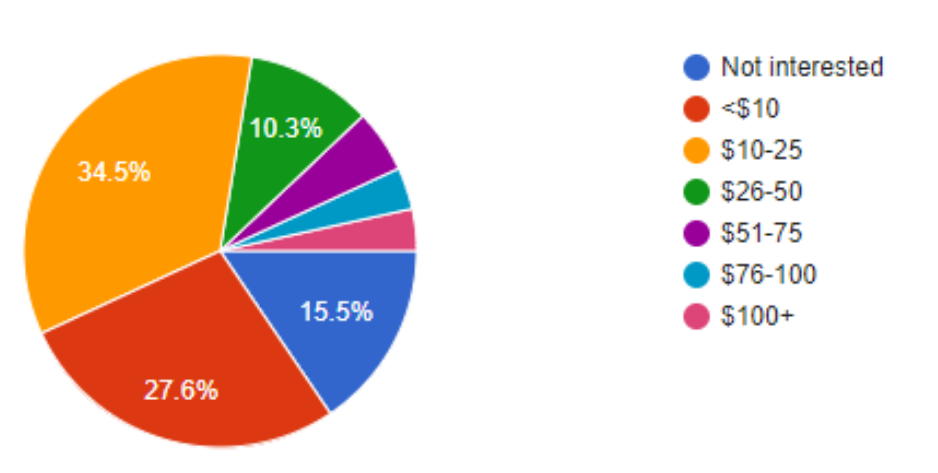
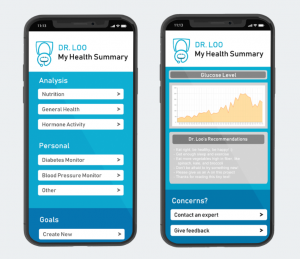
To further validate the market need and opportunity for Dr. Loo, we conducted a survey via Google Forms. Out of the 58 respondents, 73% want health diagnostics more than once a year. In addition, 57% of the respondents would pay more than $10/month for a solution like Dr. Loo.
Desired Report Frequency
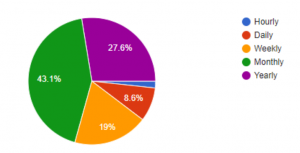
Willingness to Pay (per month)
Implementation, Roll-out, & Next Steps
For our first iteration of minimum viable product, we want to sell Dr. Loo directly to a group of end customers. Given Dr. Loo’s ability to help users maintain a healthy track record, as well as detect and prevent the progression of various illnesses, it can be marketed successfully to these customers through healthcare providers and other channels, such as health and fitness magazines and sites. These customers would face an initial cost of $200 for the purchase of the instrument (can be potentially reimbursed through insurance companies) and then a monthly subscription charge of $20 for the mobile app and replaceable cartridges.
For future steps, we want to consider selling to hospitals so that they can install these directly into their toilets and have their patients use them for quicker/more convenient test results. In addition, to make Dr. Loo more accessible to patients and broader user base, we would seek government approval for use of funds from flexible spending accounts and eligibility for reimbursement through insurance companies.
Although our first iteration focuses on urine samples, in the future we will also want to incorporate stool into Dr. Loo’s repertoire so that test results can be even more robust. Samples of stool are able to give more details on conditions that urine can’t analyze. This includes the presence of food poisoning (and gastrointestinal infections), drugs, STDs and other types of diseases. In addition to incorporating stool, we hope to enhance Dr. Loo’s range of usefulness and accuracy by doing the following:
- Pursue a more granular analysis / detailed results through microscopic exams, gas chromatography/mass spectrometry, etc.
- Partner with Labcorp and other testing agencies to ensure the latest tests are available
- Integrate with other fitness applications (i.e. Fitbit)
Another future addition would be to allow for automatic reordering of cartridges based on number of urinalysis strips left in the existing cartridge. This makes it so that users don’t even have to remember when to reorder a new cartridge, paving the way for further automation.
Budget, Cost, & Funding
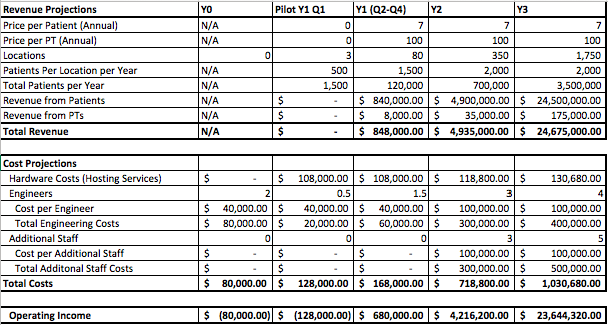
We would like to request $200k to fund Dr. Loo. We are assuming an upfront cost of $200 per unit to customers for the initial equipment (see below for breakout), plus a monthly subscription fee of $20 (for cartridges and the app), growth rate that starts off at 13% and monthly churn rate that starts off at 4% (with rates stabilizing over the months), and costs for R&D, staff, manufacturing, etc. Please see this sheet for financials surrounding growth and cost hypotheses as well as an in-depth model broken out by month for the first 2 years.
Other costs to keep in mind (also built into the model):
- $20-25k average to build initial iOS and Android apps
- Free AWS credits are available for startups to handle our analytics and basic client-server cloud-compute app, and if we could apply for an activate partnership with VC’s help, then we should be able to run for our first year without the need to spend anything on computing infrastructure.
- Shipment costs of $2 per package
The image below is a build-up of our component costs for the physical product that attaches to the consumer’s toilet.

The components alone total to an estimated $139.07 per unit. With an additional 35% premium for manufacturing and shipping, this brings us to a total cost of $187.75. We then factor in a small buffer to assume an upfront cost of $200 per unit.
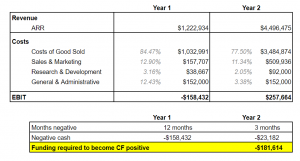
The screenshot below is tab 1 of our financials sheet and contains a snapshot of the high-level numbers. We hypothesize we will need $182k; however, we want to factor in an 18k buffer, making our total ask $200k.
Risks
We may need to go through FDA approvals for our product since it is a type of medical device. Since our initial product would use existing medical testing procedures and would not be developing them on its own, we do not anticipate needing a high-level type of approval as the risk is very low. Thus if we were to go for approval, we would aim for low-level FDA approval. In the event that the FDA disagrees, we would be able to appeal to be granted permission to do clinical testing with insignificant risk, which requires only IRB approval, or potentially turn to the EU for CE mark approval.
A related risk involves initial medical backing from medical professionals. We will need to ensure we talk to as many doctors to vet any concerns and have them be our biggest advocate in recommending this product to their patients, so that we can ensure greater adoption by end users.
Another risk to keep in mind is the issue of sample dilution. We will be using a significant portion of R&D in order to figure out how to capture the sample. One method is to have a pipette that extends into the toilet bowl and draws up a sample after each bathroom usage. This is easily the least costly method; however, it also means that we would be dealing with diluted samples, as there is already water in the toilet bowl prior to the action. Another method is to come up with some kind of funnel to capture the sample. This would ensure pure samples, however could introduce the risk of bacteria formation, greater manufacturing costs, and minor discomfort of the user.
Lastly, compared to a urinalysis sent directly to labs, dipstick testing lacks precision and is limited in the type of conditions that can be detected. Although the chemical reactions and color changes are reliable in identifying the presence of known abnormalities, dipstick testing does not quantify the seriousness of the abnormalities and their underlying causes. Therefore, in the event that a condition persists, a user would still need to follow up with a healthcare provider for further diagnosis and if necessary, to develop a treatment plan. Nevertheless, dipstick testing is still a much more convenient form of urinalysis that delivers benefits when users have no physical symptoms (and therefore would’ve left a condition undetected) and when patients require ongoing metrics to monitor their illness. As we develop the capability to deliver more granular results (i.e. through stool and microscopic testing), we can mitigate this risk significantly.
Competitors
There are several types of competitors we will have to keep in mind as we roll-out Dr. Loo. The first is the existing medical laboratory services industry. This industry is relatively concentrated, with the top two companies accounting for about 30% of the overall industry, and with further consolidation expected to take place in the coming years. There have also been a handful of competing efforts from other companies, such as Toto, to make experimental smart toilets, but none of these have made it to mass-market and because they were expensive and designed as entire toilets rather than sensors. Lastly, there are startups, such as Scanadu and S-There, that are trying to come up with technological solutions for analyzing someone’s health off their urine or feces, however these are still in their growth phase and do not have the robustness or ease that our product can deliver to customers.
Team
Siddhant Dube
Eileen Feng
Nathan Stornetta
Tiffany Ho
Christina Xiong
Sources
https://stanmed.stanford.edu/2016fall/the-future-of-health-care-diagnostics.html
http://homeklondike.site/2017/04/22/duravit-launches-a-toilet-that-analyzes-urine-tests-by-itself/
http://www.iotevolutionworld.com/smart-home/articles/434971-iot-will-influence-bathroom-the-future.htm
http://www.diasource-diagnostics.com/var/ftp_diasource/IFO/RAPU02C022.pdf
https://www.livestrong.com/article/165210-what-are-the-causes-of-wbc-rbc-in-urine/
https://drannacabeca.com/products/dr-anna-cabeca-keto-alkaline-weight-loss-solution-urinalysis-test-strips
http://medicaldevicedaily.com/perspectives/2017/05/18/new-ce-mark-rules-make-fda-seem-user-friendly-cardiovascular-devices/
https://gizmodo.com/5119681/totos-intelligence-toilet-ii-smartly-measures-the-temperature-of-your-pee-among-other-things
https://www.pcf.org/news/new-urine-test-for-prostate-cancer-available-unlike-psa-test-is-ultra-specific-for-prostate-cancer/
https://www.scanadu.com/diagnostics.html
https://www.fda.gov/MedicalDevices/DeviceRegulationandGuidance/Overview/default.htm
https://aws.amazon.com/activate/
http://howmuchtomakeanapp.com/estimates/results
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4935544/
https://www.ncbi.nlm.nih.gov/pubmed/22235952
http://clients1.ibisworld.com.proxy.uchicago.edu/reports/us/industry/keystatistics.aspx?entid=1408
http://www.diabetes.org/advocacy/news-events/cost-of-diabetes.html
http://www.diabetes.org/assets/pdfs/basics/cdc-statistics-report-2017.pdf
https://www.pbs.org/newshour/health/urine-screens-cost-8-5-billion-a-year-more-than-the-entire-epa-budget
https://www.wired.com/2015/11/c2sense/
https://www.walgreens.com/topic/faq/questionandanswer.jsp?questionTierId=700020&faqId=1200046
https://www.walgreens.com/topic/faq/questionandanswer.jsp?questionTierId=700020&faqId=1200046)
https://www.healthline.com/health/urine-ph#results
https://www.gdx.net/product/one-fmv-nutritional-test-urine
http://drwebbhealth.com/urinalysis.html
https://emedicine.medscape.com/article/2090711-overview