By Rob Mitchum // May 20, 2015
“Big data,” as vague and buzzwordy as the term is, has arguably led to major changes in finance, advertising, and elections. But it has yet to make a big splash in one of the largest and rapidly-growing sectors of the U.S. economy, health care. While there is no shortage of data in medicine, complexity and politics inhibit the transformation of this information into action: lower costs, personalized care, predictive diagnosis, and beyond.
On May 18th, a crowd gathered at MATTER in Chicago’s Merchandise Mart to hear from health and computational experts on these challenges and early glimpses of big data success stories in the field of biomedicine. MATTER, a new work space for healthcare startups and entrepreneurs, was the ideal setting for “The Power in Patterns: How Big Data is Improving Patient Care,” a discussion by Jonathan Silverstein of NorthShore HealthSystem and Ian Foster and Rayid Ghani of the Computation Institute, each of whom developed their own approaches to break through these barriers between data and health care.
Silverstein, a former deputy director of the CI, is the Chair for Informatics at NorthShore, the first hospital system in the U.S. to implement a comprehensive electronic health record way back in 2003. That head start provided NorthShore with a leading “data warehouse,” holding the records of roughly 2 million patients. While this data adds up to “only” 8 terabytes — relatively miniscule in the world of “big data” — the system has already developed useful new tools on the back of this rich information base.
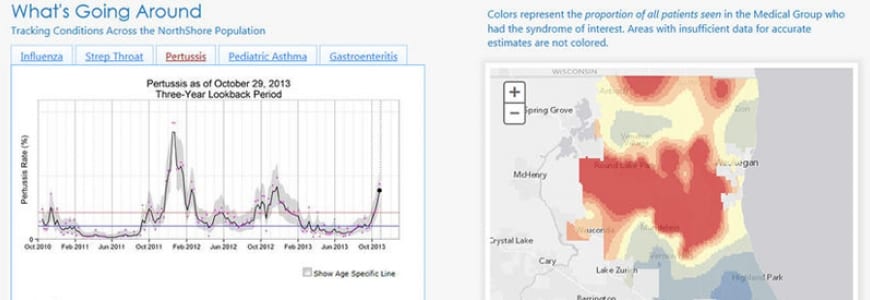
For example, a NorthShore team developed a model that predicts undiagnosed hypertension using blood pressure data, alerting doctors in real time during outpatient visits. An application called “What’s Going Around” uses live data about the spread of infectious diseases across their patient population to notify physicians about currently active illnesses near a patient’s home address. Ongoing campaigns recruit patients to voluntarily input family history and genomic data into the EHR database, for deeper research and medical care. And new techniques for converting two-dimensional medical images into 3D-printed objects help surgeons prepare for the unique anatomy of each patient.
Many of these innovations fit the long-anticipated model of personalized medicine, moving healthcare from treatments based on populations to treatments customized for individuals. New data sources and analytic methods may offer the precision to make these ambitions possible in the near future.
“We need to do a better job of finding small subgroups within a group of things that look the same,” Silverstein said.
Ian Foster, director of the Computation Institute, demonstrated how solutions developed for fields, such as physics and astronomy, that struggled with “big data” problems before medicine can help health care researchers find new discoveries within their own data flood. As an example of the challenges, he showed a diagram from CI Senior Fellow Funmi Olopade, which illustrated the tangled web of data movement between dozens of different resources and personnel working with her cancer genetics laboratory.
“One of the biggest obstacles to data-driven biomedicine and science is that data is not easily shareable,” Foster said. “We don’t have the equivalent of Facebook or Flickr for data.”
But cloud computing advances made by CI research center Globus and the Genomic Data Commons (led by CI Senior Fellow and Faculty Robert Grossman) promise to untangle these knots. Globus allows researchers to easily move, share, and publish large amounts of data, and through its Globus Genomics platform, scientists can also analyze data in the cloud, using virtual computers from Amazon. The Genomic Data Commons will gather all available cancer data into a single resource so that researchers can compute over the information to find new treatments and discoveries.
“Individuals can no longer eyeball a petabyte of data and extract meaning from it,” Foster said. “You need computers to extract knowledge from it.”
Rayid Ghani, director of the Center for Data Science and Public Policy (DSaPP) and the Data Science for Social Good (DSSG) fellowship, put health care into the broader context of the “big data” era and what has been accomplished so far. Though the amount of data has grown in recent years, most of the statistical methods used on that data are decades old, Ghani said, and mostly used for the same basic reasons: description, detection of patterns or anomalies, and predictions. For health care and other fields, the next step will be moving beyond prediction to intervention, he argued.
“After prediction, what’s next?,” Ghani asked. “Prediction is useful and interesting but often not enough in isolation, because if you can’t do something about it, can’t change a phenomena or behavior, you’re just watching.”
To illustrate the difference, Ghani talked about his group’s work with the Chicago Department of Public Health on preventing lead poisoning in local children. Currently, the CDPH inspects a home for lead only after a child is found to have elevated blood levels — “using kids as sensors, that’s the unfortunate state of the art today,” Ghani said. But a DSSG project in 2014 and subsequent work by DSaPP created a predictive model that identifies homes at high risk of contamination, and children at risk of poisoning, before exposure occurs. Crucially, the model will now be used by CDPH to deploy home inspectors and by physicians to identify children that may require earlier or more frequent blood tests, transitioning the work from research to real world impact.
While these early success stories with medical data demonstrated the great promise of the approach, it also showed how much work was left to be done. Audience questions for the panel focused on the political barriers to data sharing, particularly in a medical environment where patient privacy must be protected. But with the great incentives — both financial and humanitarian — around health care, further innovations are likely for how health care data is collected, managed, analyzed, and applied.