Opportunity:
Financial Broker-Dealers such as Goldman Sachs, JP Morgan, and Morgan Stanley are constantly monitoring their trading activity for errors, particularly in the Over-the-Counter or OTC market, where trades are done off of exchanges and are bilateral agreements between parties with bespoke terms.
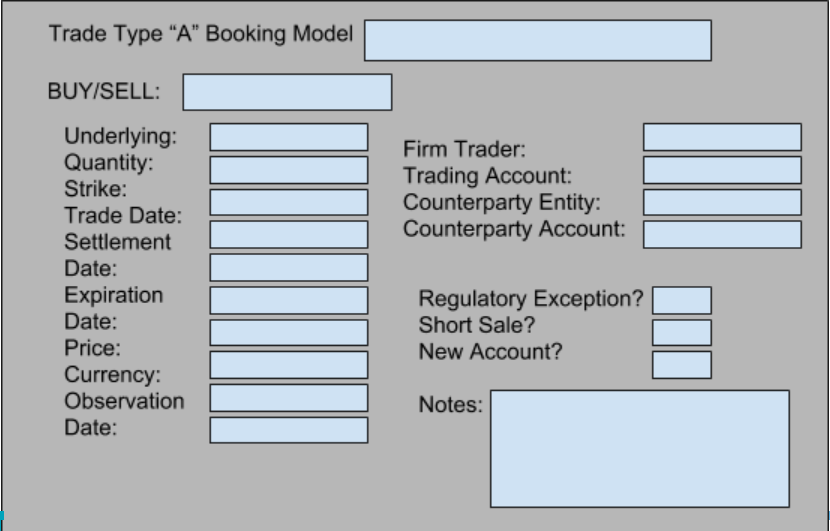
Simple, “vanilla” products such as Calls and Puts may have as many as 15 relevant fields, but structured products and exotic derivatives may have upwards of 100. Each field is negotiated and confirmed with counterparties on the “street” in a multi-level proofreading and verification process that can take anywhere from three days to two weeks or more. Errors on the direction of a trade, the underlying asset a derivative references, the size, strike, or expiration date are all relevant economic factors that can significantly damage the profit margin, reputation, and volume capacity of a given securities business.
It is in the interest of Investment Banks to mitigate the risk they incur within this OTC market by intelligently sensing where potential risk may lie and devoting resources accordingly. However, the current model involves visual, manual reconciliations performed by specialists on an ad hoc, continual basis with each trade, and field, reviewed as it comes.
Process for Confirming and Controlling OTC Trades Currently:

Generic Sample OTC Option Ticket:
Commercial promise and challenges:
According to the Bank of International Settlements (BIS) the outstanding notional amount of OTC derivatives exceeded $416 Trillion globally, with a gross market value of $13 Trillion.
Utilizing these assumptions as well as error rates and sizes provided by conversations with industry experts we create an estimated total addressable market and assign a value to the potential industry savings annually per incremental improvement in error reduction:
| Number of Major Broker-Dealers | 25 |
| Average Transactions | 100 |
| Market Transactions / Day: | 2,500.00 |
| Yearly Transactions: | 625,000.00 |
| Gross Market Value: | $ 13,000,000,000,000.00 |
| Error Rate: | 3.0% |
| Average Value of Error: | $ 5,000.00 |
| Annual Error Cost: | $ 93,750,000.00 |

Hence, a reduction in the error rate by 1% and error size by $1,000 would yield annual savings of approximately ~$44mm, whereas a 2% reduction and $3,000 reduction saves ~$80mm. Thus, even a small market penetration rate with moderate success could be significant.
The principal challenge would be in getting Investment Banks, which closely guard their internal affairs, to be willing to integrate an outside vendor’s technology in their operations without having direct control over that entity and in addition having that entity service other banks. Furthermore, the usage of this technology to reduce error rates in an opaque and poorly-understood market, which is the reason for the opportunity in the first place, does not lend itself well to clear-cut spending decisions. Therefore getting buy-in for COO’s and CTO’s will be a lengthy process and require imaginative data visualizations and proof of data security.
Competition:
We face competition on two fronts, internal to Broker-Dealers and externally in the form of “RegTech” companies seeking to provide tailored AI Solutions. Internally, there are significant resources available to banks within their IT departments, however, the deployment of those resources to such targeted AI solutions is limited at current due to the intense product-specific knowledge requirements that are often siloed. Externally, there are numerous RegTech companies which primarily focus on compliance rather than financial risk. AQMetrics and Ancoa, which received the 2016 Operational Risk Award, both are focused on automated auditing of transactional data and real-time trader behavior surveillance. These companies thus pose the greatest direct threat.
Proposed alteration:
Model Design:
- Data from email, chat, firm booking systems, issue trackers, integrated in a pipeline to create a dataset for analysis. Historical testing and scenario analysis used to create weightings of risk for fields/attributes.
- Using Supervised Learning we will use cross-validation and other techniques to tune hyperparameters on predictive indicators of the risk a particular trade has
- We believe this should be constructed as follows:
Risk (1-100) = F(Trader Behavior, Objective Risk)
Trader Behavior = F(Historical Error Rate, Estimated Error Rate)
Estimated Error Rate = F(Trade Complexity, Number of Trades, Time of Day, Experience Level, etc)
- Issues will be prioritized based on the risk construct and highlighted for further investigation
The model will create informative risk parameters for each trade that will be incorporated into the prioritization of the item either in terms of rigor of checks (can be automated via email/UI interface) or legacy human-performed checks. Large-significance errors will be disproportionately targeted by the model’s tuning. Long-term, the risk identification process will precede trade booking and help establish a more rigorous booking process at the origin. This will skew control processes to reduce error size and frequency measurably.
Sources:
https://www.investopedia.com/exam-guide/series-65/alternative-investments/derivative-securities.asp
https://www.investopedia.com/terms/o/otc.asp
https://www.bis.org/statistics/about_derivatives_stats.htm?m=6%7C32%7C639
http://stats.bis.org/statx/srs/table/d8
http://www.tearsheet.co/bigger-data/10-regtech-companies-gaining-momentum
http://aqmetrics.com/products/
https://www.crunchbase.com/organization/ancoa-software#section-overview
Mean Error Size and Error rate estimated based on conversations with Operations Professionals from Goldman Sachs and UBS Securities