Opportunity:
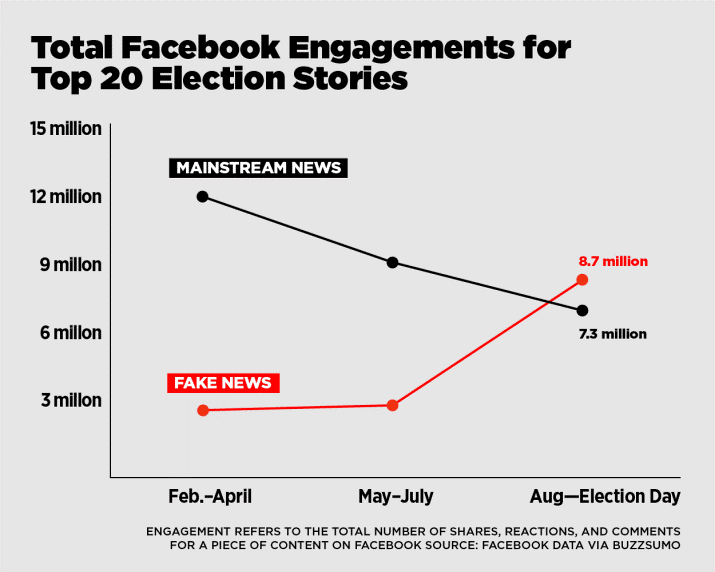
Fake news is not a new phenomenon by any means. However, in the last 12 months, the engagement of users across fake news websites has increased significantly. In fact, in the final 3 months of the 2016 election season, the top 20 fake news articles had more interactions (shares, reactions, comments) than the top 20 real articles.1 Furthermore, 62% of Americans get their news via social media, while 44% use Facebook, the top distributor of fake news.2 This represents a major shift in the way individuals receive information. With the dissemination of inaccurate content, people are led to believe misleading and often completely inaccurate claims. This will lead people to make incorrect decisions and embodies a serious threat to our democracy and integrity.
Media corporations are recovering from playing a part in either disseminating this news or inadvertently standing by. Governments have ordered certain social media sites to remove fake news or else face a hefty punishment (e.g. $50 million by Germany).3 Companies like Google and Facebook are scrambling to find a solution.
Solution:
Check Yourself (CY) provides real-time fact checking solutions to minimize the acceptance of fake news. It combines natural language processing techniques with machine learning techniques to immediately flag fake content.
The first approach will be to identify whether the article is fake based on semantic analysis. Specifically, it will connect the headline with the body of the text, see if they are related/unrelated, and then see if the content supports the headline. Verification would happen against established websites, fact trackers, and other attributes (e.g. domain name, Alexa web rank).
The second approach involves identifying website tracker usage (ads, cookies, widgets) and patterns over time and language, connecting them with platform engagement (Facebook, Twitter), and linking them with each other. This will result in a neural network where the algorithm is able to predict the probability that the source is fake.
Using an ensemble approach, combining ‘front-end’ and ‘back-end’ methods, leads to a novel solution. After designing the baseline algorithm in-house, we will then use crowdsourcing to improve upon the algorithm. Given the limited supply of data scientists in-house, it would be best to generate ideas from all disciplines, maximizing our success potential.
Pilot:
We will publicly pilot test our application through a live primary debate after we have done rigorous internal checks. As the candidates speak, information they say that is false (e.g. “The economy grew by 6% in the last year”) will be relayed to the interviewer. Additionally, the false information will also be displayed on the TV for consumers to see. At the end of the show, a bi-partisan expert panel along with fact checkers will verify whether the algorithm was accurate. Assuming a successful experiment, this has the power to allow interviewers to fact-check any claims on the spot, ensuring their viewership is well informed.
The Competition:
Currently, many companies trying to solve this problem. Existing solutions encompass mainly fact checkers, but they are not as comprehensive in their approach as we are. Furthermore, these solutions are not real-time. Universities are also trying to solve this problem but are doing so with small teams of students and faculties. The advantage we have over universities as well as companies like Google and Facebook is that crowdsourcing the solution allows for the best ideas in a newly emerging area.
Market Viability:
Even though our value proposition affects companies and customers, we will primarily start with B2B in order to build credibility and then expand to B2C. Large media companies have around 10-20 fact checkers on staff for any live debate or otherwise. This results in an average value of $600-$1.2M (assuming they spend $60k per checker per year). Furthermore, they often use Twitter and Reddit and would find our service invaluable to confirm the veracity of statements/claims immediately. Once we are established, we will move towards a B2C freemium model.
Sources:
1https://www.buzzfeed.com/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook?utm_term=.nbR6OEK6E#.ghz5aZk5Z
2https://techcrunch.com/2016/05/26/most-people-get-their-news-from-social-media-says-report/
3https://yourstory.com/2017/04/faceboo-google-fake-news/