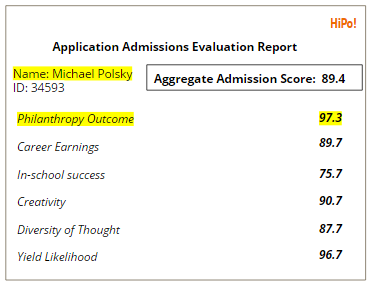
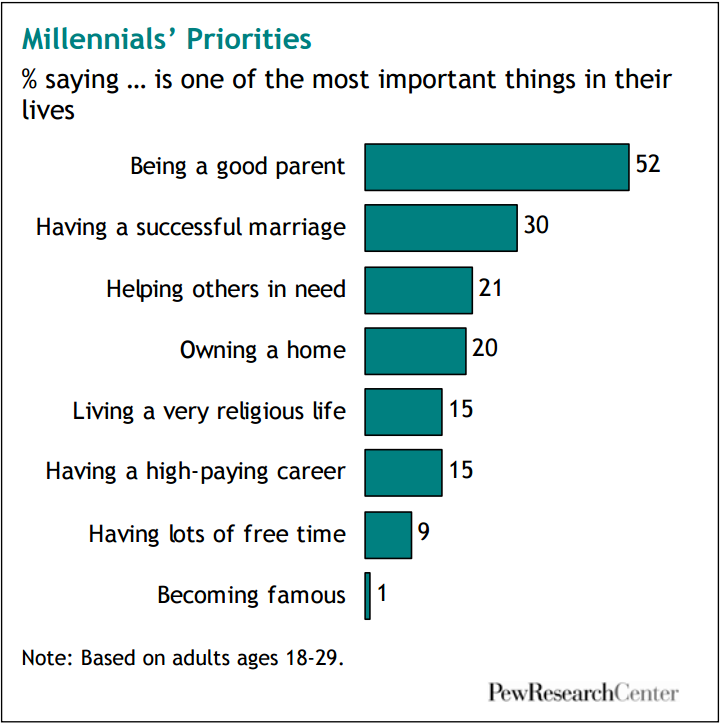
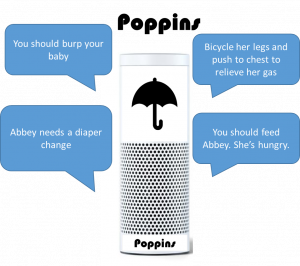
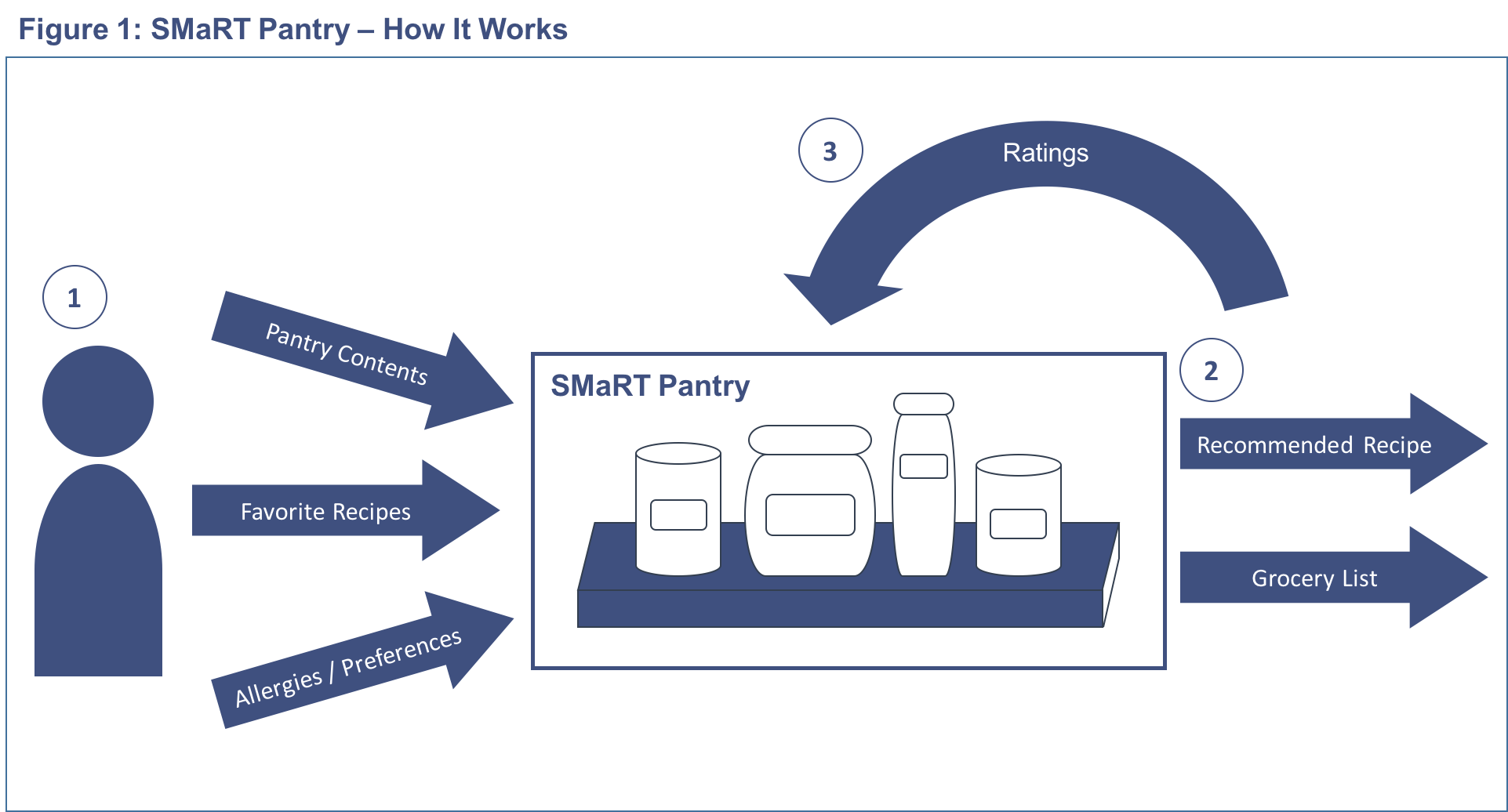
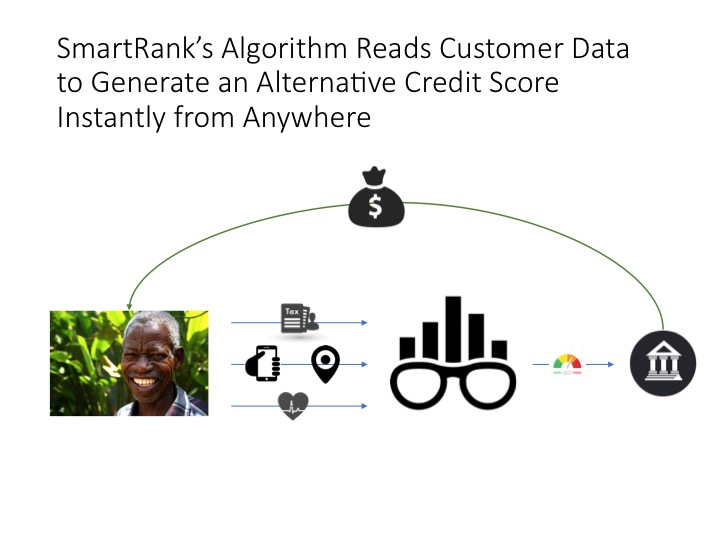
The problem: violent crimes on the rise in U.S. cities
Crime rates have remained steady or even decreased in major metro areas across the U.S. in the last decade. However, violent crimes have increased over the same time period. Social and political pressures around law enforcement reform continue to mount across the country, forcing police departments to focus on reducing violent crime rates while limiting police force discrimination.
As a trend, crime tends to proliferate in areas where it has successfully been carried out previously1. Furthermore, the severity of crime tends to escalate in those areas. In a neighborhood where an individual can get away with graffiti, the next crime may be theft or burglary, and so on. Increasing staff and patrols is not a scalable measure. In order to more efficiently prevent crime rather than react to it, police departments are turning to data.
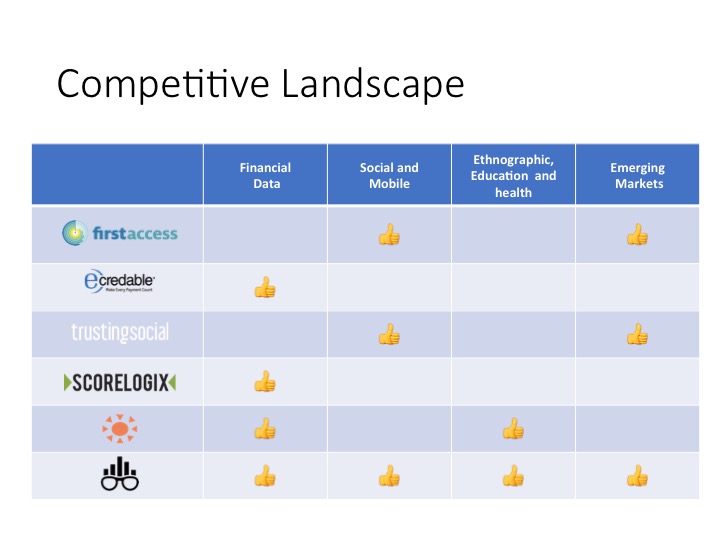
Solution: predictive policing
Predictive policing has emerged as a method to leverage data in order to predict locations where crime is likely to occur. Through a machine learning algorithm, it takes past crime data and identifies people at risk socially, as well as areas where crime is more likely.
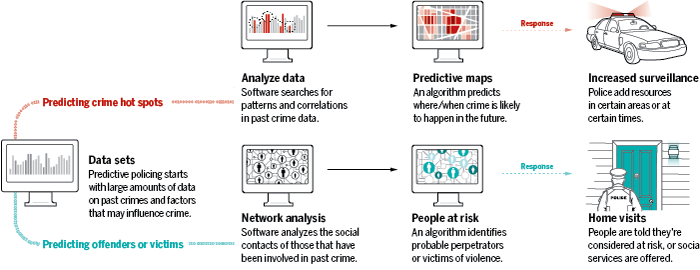
Source: http://www.sciencemag.org/news/2016/09/can-predictive-policing-prevent-crime-it-happens
One of the most dominant companies in the predictive policing space is PredPol2, a private predictive analytics service that takes data from a local department and uses a machine learning algorithm to produce a daily output of predicted future crimes. The aim of predictive policing is not necessarily to predict the type of a crime, but to predict the location and time it will occur. The goal is to allow individual departments to position police in the best locations to discourage localized criminal activity.
How does it work? First, PredPol takes several years of data to lay a background level of crime activity and map data across the local area. This is done using an Epidemic Type Aftershock System (ETAS), similar in concept to the way scientists predict earthquakes. PredPol takes data from a police department’s Record Management System (RMS) daily to collect information and inform the algorithm. According to the PredPol website, they use three key metrics: date/time, location and crime to predict the location and time of future crimes. This translates into a report with pink boxes indicating areas with high potential for crime that police should patrol.
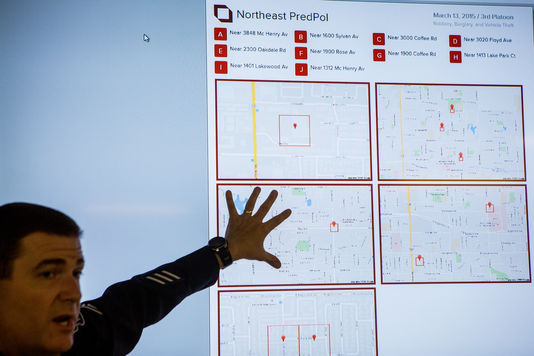
PredPol “Pink boxes” of high traffic crime areas. Source: PredPol.com
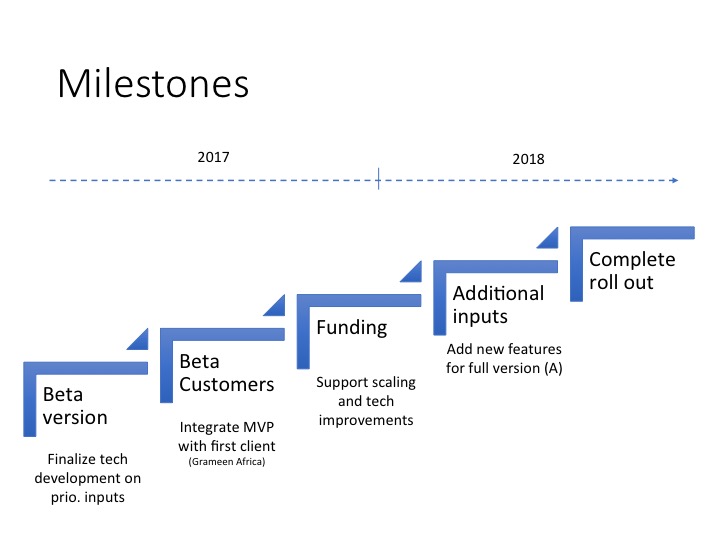
Effectiveness
PredPol cites anecdotal successes such as a 20% reduction in crime in LA over the course of a calendar year. However, it is difficult to validate such claims. Because the algorithm is proprietary, outside academics and data scientists are unable to provide accurate assessments. The RAND report is the most comprehensive third party review to date of predictive policing, and concludes that the impact of predictive policing is lukewarm at best. In fact, preliminary results show that with increased predictive power there are diminishing returns.
One of the issues with understanding its effectiveness is it is unclear what the benchmark for success should be. As one article cites, it could be argued that what PredPol actually predicts is future police activity3. Without reliable proof of causation, we are left with doubts as to whether PredPol actually reduces crime, or if its predicted police movements coincide with activities that would have occurred anyways.
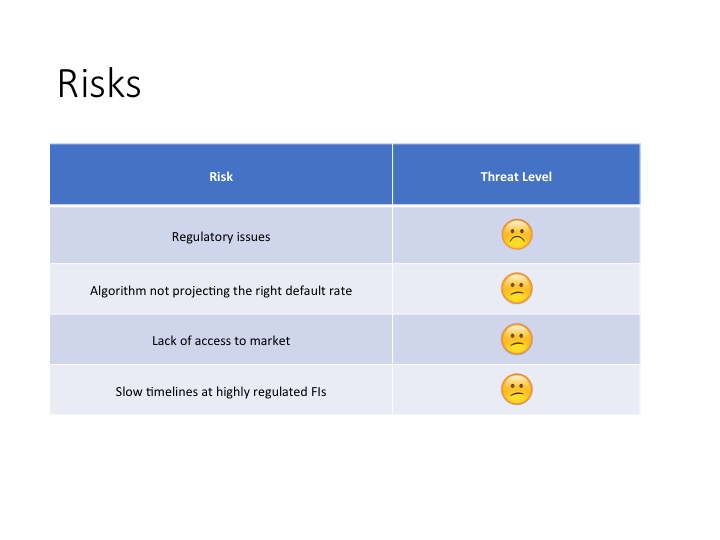
Challenges and proposed alterations
Two primary challenges face PredPol, and organizations like it. The first is proving that the algorithm actually helps businesses fight crime. More academic research from institutions with the ability to effect randomized control trials needs to be developed. One proposed solution would be to measure changes in police behavior during idle times3, i.e. when they are not on patrol or responding to a call. If PredPol’s pink boxes encouraged them to patrol an at-risk area they would have otherwise missed, then it may be easier to measure effectiveness in a controlled setting.
Second, the organization needs to provide evidence that it does not encourage racial profiling. While in marketing materials, PredPol makes soft claims that it is unbiased, by its very nature it is bringing further focus on black and brown neighborhoods. This may further encourage racial and social bias of police officers through confirmation.
References
- http://www.sciencemag.org/news/2016/09/can-predictive-policing-prevent-crime-it-happens
- http://www.predpol.com/results/
- http://www.slate.com/articles/technology/future_tense/2016/11/predictive_policing_is_too_dependent_on_historical_data.html
- http://www.economist.com/news/briefing/21582042-it-getting-easier-foresee-wrongdoing-and-spot-likely-wrongdoers-dont-even-think-about-it