
Services of the OCHRE Data Service (ODS)
Service Options
The OCHRE Data Service can help you design, collect, curate, integrate, analyze, publish, and archive your data. We provide consultation and supporting services to assist research projects with the adoption and use of the OCHRE database platform.
See Project Services for more information regarding the process and the fees for becoming an OCHRE project and taking advantage of our services.
Call (773-702-1352) or contact us to discuss your research project’s specific needs.
CONSULTATION AND TECHNICAL SUPPORT
Our experienced research database specialists are available to help you determine whether the OCHRE database system is a good fit for your research project.
- Discuss your data with you and work to understand the research needs of your project
- Help you appreciate how best to organize your data using the flexible OCHRE data model
- Walk through the options for managing your images, PDFs, and other supporting files
- Demonstrate a variety of techniques for analysis and publication
- Plan an appropriate archival strategy
- Support implementation of a database solution
We are often also available at conferences, either as exhibitors or as presenters, and we are always happy to discuss how the OCHRE platform provides solutions for research projects. Check our Schedule of Events to see if we are coming to a city near you.
DATABASE SERVICES
Project data is stored in an XML-based, graph database on a server managed by the Digital Library Development Center at the University of Chicago. Note that OCHRE distinguishes between internal data stored in the XML format within the central database and external digital resources such as images, spatial data, 3-D models, and video recordings. Each project will normally provide its own Webserver on which to store its images and other external resource files. These files are not stored in the central OCHRE database but are simply catalogued there,with links to the Internet locations where they can be found.
OCHRE does not impose database terminology on your core project data. All project descriptors are customizable. Our research database specialists will help users build a taxonomic hierarchy (data dictionary or vocabulary), an important step in data modeling. User-interface tools are provided to shield the project team from technical complexities.
IMAGING SERVICES
The OCHRE Data Service can provide a variety of unique and powerful imaging services.
First, we can provide Reflectance Transformation Imaging (RTI), a photographic method that uses computational techniques to create images of items having low relief. This type of photography is particularly useful in the documentation of inscriptions, seal impressions, and certain fossil impressions. In fact, this photographic method has potential value for imaging any object that contains details that are best visible when viewed under various lighting angles. RTI photography is not limited by the size of the object. Our photographers have imaged objects smaller than 1 cm diameter and larger than 20 feet wide.
In addition to RTI, the OCHRE Data Service provides high quality digital scanning using a BetterLight scanner. While the best Canon DSLR cameras provide images in roughly 21 megapixel resolution, our BetterLight scanner can provide images in excess of 200 megapixels. This photographic method is useful for art reproduction or any application that requires highly accurate, high resolution images.
Our photographers have years of experience in professional photographic methodology including studio lighting and filtering. We are also accomplished archaeology field photographers with expertise in the use of aerial photography for photogrammetric modeling.
We can help you produce quality images. But more importantly, in the OCHRE data model, these images of various types are integrated with and linked to your project data, creating a rich analytical network.

Miller Prosser doing RTI photography in the OI photo lab
PUBLICATION SERVICES
Data in OCHRE can be published to the Web at the discretion of the project team. This is a process that leverages the OCHRE API. “Right-click, Publish” and your data can be available on the web. The OCHRE Data Service is developing web templates and publication formats that can be used for default out-of-the-box publication of typical OCHRE data.
View some simple examples of sample published pages of OCHRE data.
OCHRE TO THE RESCUE (Legacy data conversion)
More and more the OCHRE Data Service is being called on to rescue legacy data from single-purpose spreadsheets, aging applications, or obsolete formats. Most of our new projects also have data already in digital form that they want to have imported automatically into OCHRE. We have a lot of experience as data janitors, preparing the data for the strict requirements of OCHRE’s item-based approach, and have developed special utilities for importing such data into the OCHRE platform. This is generally a somewhat complex process which requires our technical support in collaboration with the project team.
Typically, the data to be imported is in the form of two-dimensional tables consisting of rows and columns (e.g., in a Microsoft Excel spreadsheet, or converted to that format in order to be imported into OCHRE). Hierarchical relationships are often embedded in such tables, especially in tables of archaeological data, in which the first few columns contain contextual information at successively smaller scales of measurement (e.g., site, area, trench, layer). This information is used to construct spatial hierarchies automatically within OCHRE. Likewise, the property values (attributes) stored in table columns are used to create item properties in OCHRE.
In the case of philological projects that deal with ancient texts written in complex scripts (e.g., cuneiform texts from the ancient Near East), text files containing transliterations of the original texts can be imported automatically into OCHRE. Line breaks, white space, hyphens, capitalization, font size, and other features of the text file are used to parse the text, exposing the analytical distinctions embedded in the transliteration. OCHRE will automatically construct detailed epigraphic and discourse hierarchies to represent the text and to capture the existing analysis of it.
The main challenge in importing existing data is to clean up errors and inconsistencies which often become painfully apparent when data files are converted to the OCHRE format. After the automated import process is completed, some manual editing within OCHRE may be required in order to take advantage of OCHRE features. Once the data is in OCHRE it is generally more consistent and more richly linked than it had previously been. It is also available, then, for online publication using the OCHRE API or for export to a variety of other formats for use external to OCHRE.
ONSITE DATA MANAGER (Archaeology projects)
The OCHRE Data Service can provide your archaeological project with an onsite data manager during your active excavation season. Our experienced, tech-savvy, student or junior archaeologists are skilled at problem-solving, multi-tasking, and facilitating the data capture of all aspects of a real-time archaeological project while in the field.
Your project covers travel expenses and room and board. We provide a high-energy, dedicated OCHRE expert. References are available on request.

OI PhD student, onsite data manager, Zincirli 2018
GEOGRAPHIC INFORMATION SYSTEM (GIS) SERVICES
The OCHRE Data Service staff and student assistants have a range of GIS expertise with popular tools such as QGIS, ArcMap, ArcPro, and ArcGIS Online. OCHRE has a Map View feature that supports many common formats natively, like geo-referenced rasters and shapefiles.
Read our “Success Story” – Georeferencing the Past – on the Esri Developer’s Showcase.
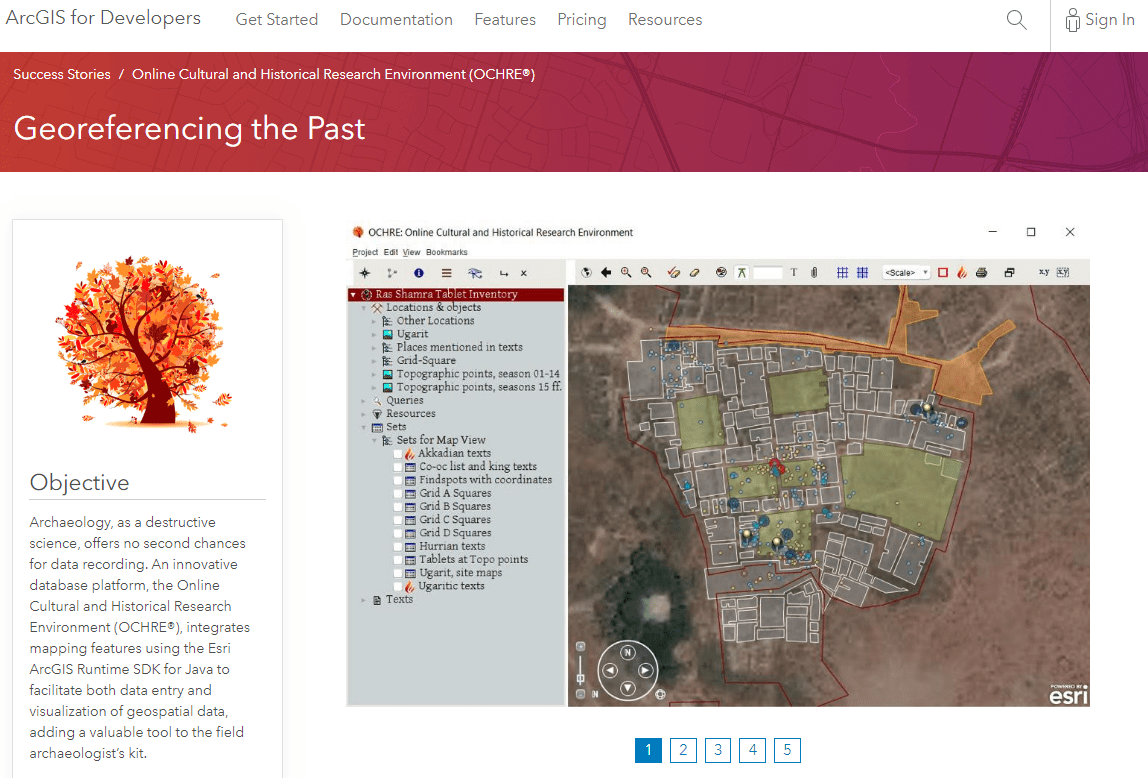
Georeferencing the Past: Esri Success Story