- Opportunity
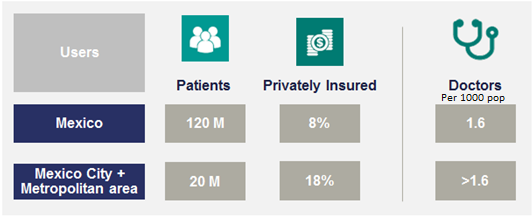
According to Pew Research poll, 40% of Americans use online dating(1) and 59% “think online dating can be a good way to meet people”(2). UK country manager of a dating app, eHarmony, Romain Bertrand mentioned that by 2040, 70% of couples will meet online(3). Thus, the online dating scene is a huge and ever growing market. Nevertheless, as of 2015, 50% of the US population consisted of single adults, only 20% of current committed relationships have started online, and only 5% when it comes to marriages(1). There is a clear opportunity to improve the success rate of dating apps and improve the dating scene in the US (for a start). As per Eli Finkel from Northwestern University (2012) (3), likelihood of a successful long-term relationship depends on the following three components: individual characteristics (such as hobbies, tastes, interests etc.), quality of interaction during first encounters, and finally, all other surrounding circumstances (such as ethnicity, social status etc.). As we cannot affect the latter, dating apps have been historically focusing on the first, and have recently started working with the second factor, by suggesting perfect location for the first date etc. For individual characteristics, majority of dating apps and websites focus on user-generated information (through behavioral surveys) as well as user’s social network information (likes, interests etc.) in order to provide dating matches. Some websites, such as Tinder, eHarmony and OkCupid go as far as to analyze people’s behavior, based on their performance on the website and try to match the users to people with similar or matching behavior.
Nevertheless, current dating algorithms do not take into account vital pieces of information that are captured neither by our behavior on social media, nor by our survey answers.
- Solution
Our solution is an application called “Latch” that would add the data collected through wearable technology (activity trackers such as Fitbit), online/offline calendars, Netflix/HBO watching history (and goodreads reviews), and user’s shopping patterns via bank accounts to the data currently used in apps (user-generated and social media) in order to significantly improve offered matches. According to John M. Grohol, Psy.D. from PsychCentral, the following are the six individual characteristics that play a key role in compatibility of people for a smooth long-term relationship (4):
-
- Timeliness & Punctuality (observable via calendars)
- Cleanliness & Orderliness (partially observable – e-mails/calendars)
- Money & Spending (observable via bank accounts)
- Sex & Intimacy
- Life Priorities & Tempo (observable via calendars and wearables)
- Spirituality & Religion (partially observable via calendar, social media, Netflix/HBO patterns, and e-mail)
Out of the six factors mentioned above, 5 are fully or partially observable and analyzable through the data already available online or offline via the sensors mentioned earlier. As all the information we would request digs deeper into privacy circle of a target user, we would be careful to request only information that adds value to our matching algorithm and will use third-parties to analyze such sensitive info as spending patterns.
- Commercial Viability – Data Collection
The dating market size has reached $2.5 billion in 2016(6), there are over 124 million accounts registered on online platforms.As a new company entering the market Latch would have a clear advantage over the current incumbents, as it would not have to use old and commonly used interface of dating process. As per Mike Maxim, Chief Technology Officer at OkCupid, “The users have an expectation of how the site is going to work, so you can’t make big changes all the time.”Prior to the launch, we would have to collect initial information. In order to analyze only the relevant data we would have to analyze the behavioral patterns of current couples before they started dating. Thus, we would aggregate data available on their historical purchase decisions and time allocation in order to launch a pilot.
- Pilot
The pilot version will be launched for early adopters based on human- and machine-analyzed historical data of existing couples. Step 1 – Collecting Initial DataOur initial observation pool will be University of Chicago and peer institution students. We chose this group of people, as in order to compile the initial data on compatibility we would need to have a trust of people providing us with their private information, such as email accounts. We will start by approaching existing couples across the universities, focusing on couples that were formed recently. In order to attract as many students as possible, we will offer university-wide benefits, such as cafeteria coupons, book discounts etc. As a result, we will collect historical information (before the start of a relationship) on social media, e-mail, calendar, fitbit and other activity from tools mentioned earlier, by gaining access to respective accounts etc. Step 2 – Analyzing the data
We will combine all the collected data and observe for recognizable and significant patterns. For example, how much being early birds or night owls have hustatistically significant effect on the likelihood of them matching their partners etc. Using machine learning we will analyze the data until we find all the significant variables that contributed to the likelihood of our existing couples matching. We will be focusing on the following observable characteristics in each tool used:
| Tool | Characteristics |
| Calendar Accounts |
|
| E-mail Accounts |
|
| Social Media |
|
| Entertainment Accounts |
|
| Fitbit |
|
| Bank Accounts |
|
Step 3 – Attracting Early Adopters / Market adoption
Based on the compatibility variables derived from the initial observation pool analysis, we will attract early adopters. In order to attract early adopters we will position ourselves as the new dating app that uses a much broader set of data in order understand the user and find him/her the perfect match.
Create awareness:
In order to attract early adopters we plan to promote the app during events that attract large numbers of people, such as musical concerts, sport events and various fairs. We would also offer promos around important holidays, such as Valentine’s day or New Year Eve.
From Awareness to Download to Use:
U.S. Millennials have 3-4 dating apps installed on their phones on average due to the low quality of matches, all of them require attention (e.g. swipes, coffee beans etc.) and can be quite frustrating, hence we will promote usage by directly addressing the low return-on swipe utility.
In order to lower the churn rate that is very high for any given app (50% per year)(7), we would make the initial registration very easy: no long surveys to be filled out, only linking your social media account (facebook). Once the user starts using we will show improvement opportunities for higher quality matches by adding additional sources of data such as e-mail accounts, calendar accounts, other social media accounts (incl. professional), entertainment accounts (Netflix, Audible, Amazon Prime etc.). Once the user starts using the app we will offer more time consuming opportunities such as answering survey questions developed by behavioral psychologists.
Step 5 – Growth
Second Phase Expansion 1. Future expansion opportunities exist in increasing the number of information sources once the user base is large enough. On top of existing data sources (e-mail accounts etc.) we will expand into integrating DNA ancestry information (such as provided by MyHeritage DNA) as well as medical history information.
Second Phase Expansion 2.
Using the collected user preference data we will expand into offering perfect first date setups, such as movies that would be liked by both users. This will create monetization opportunities for referencing users to events and restaurants.
- Team:
Alexander Aksakov
Roman Cherepakha
Nargiz Sadigzade
Yegor Samusenko
Manuk Shirinyan
- Sources:
- http://www.eharmony.com/online-dating-statistics/
- http://www.pewresearch.org/fact-tank/2016/02/29/5-facts-about-online-dating/
- http://www.telegraph.co.uk/technology/news/12020394/DNA-matching-and-virtual-reality-The-world-of-online-dating-in-2040.html
- https://www.washingtonpost.com/news/the-intersect/wp/2015/11/11/the-one-thing-about-matching-algorithms-that-dating-sites-dont-want-you-to-know/?utm_term=.20846eb81ca8
- https://psychcentral.com/blog/archives/2014/10/08/6-absolute-must-haves-for-relationship-compatibility/
- http://blog.marketresearch.com/dating-services-industry-in-2016-and-beyond