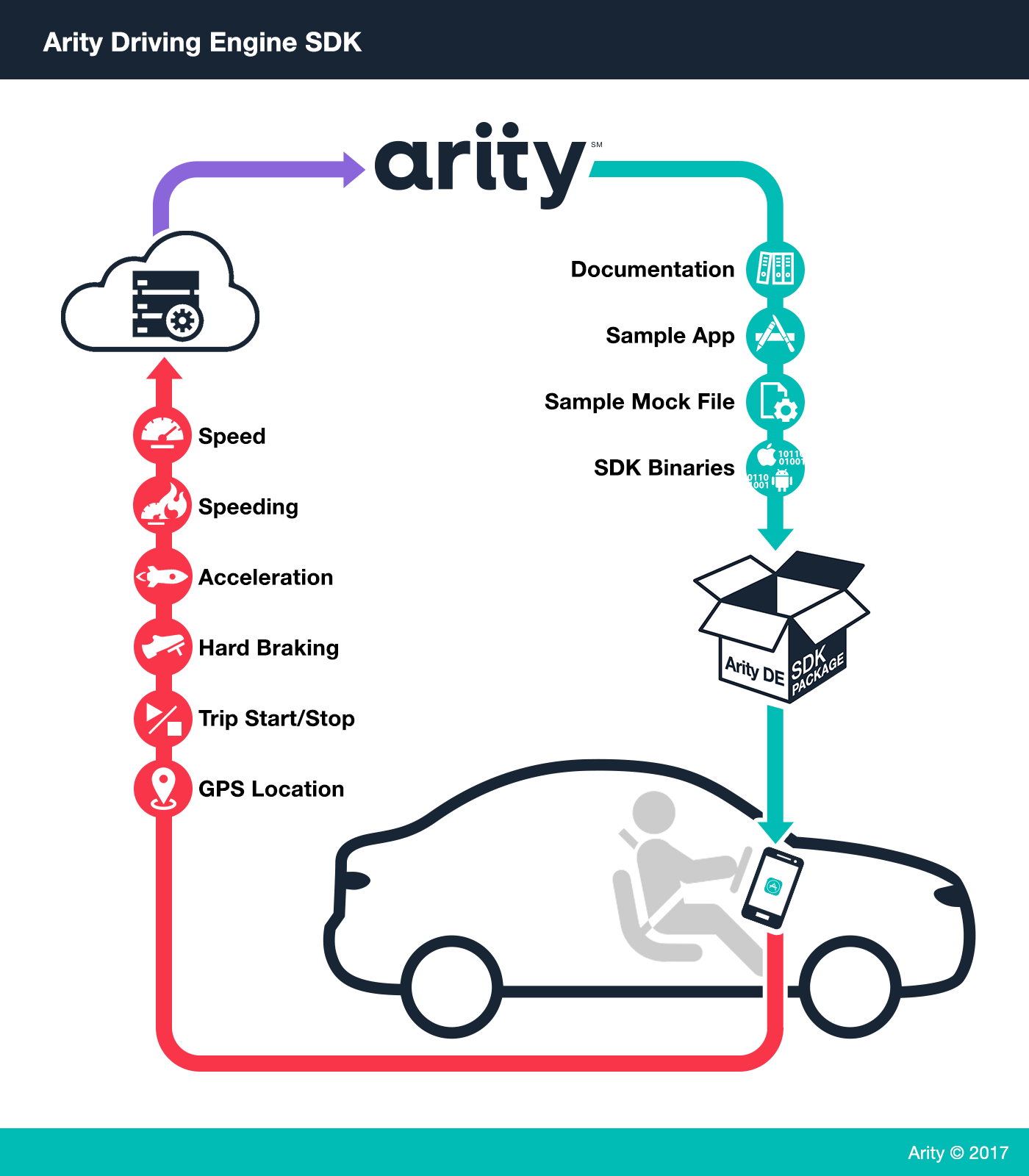
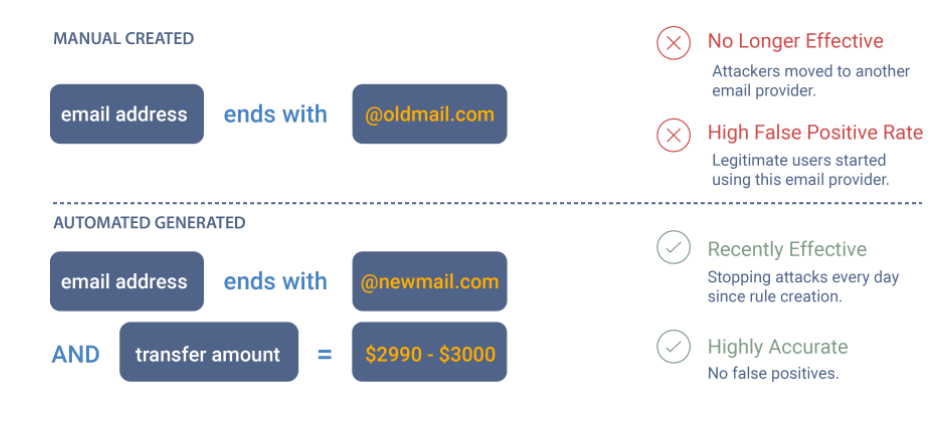
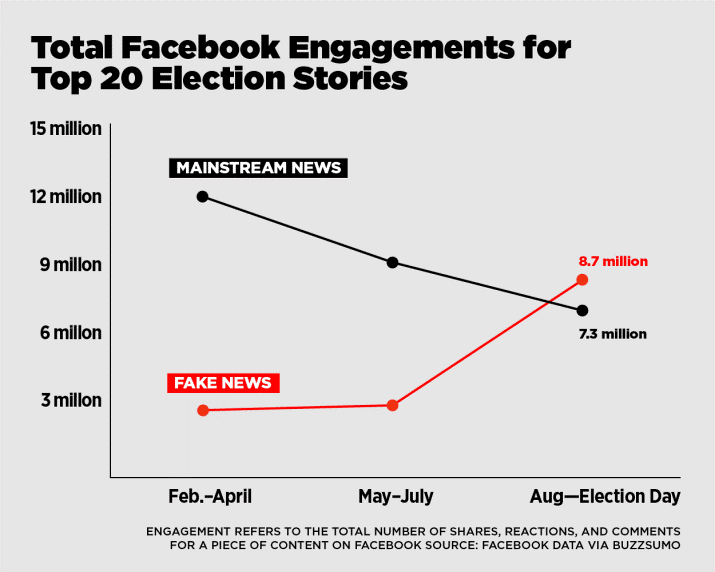
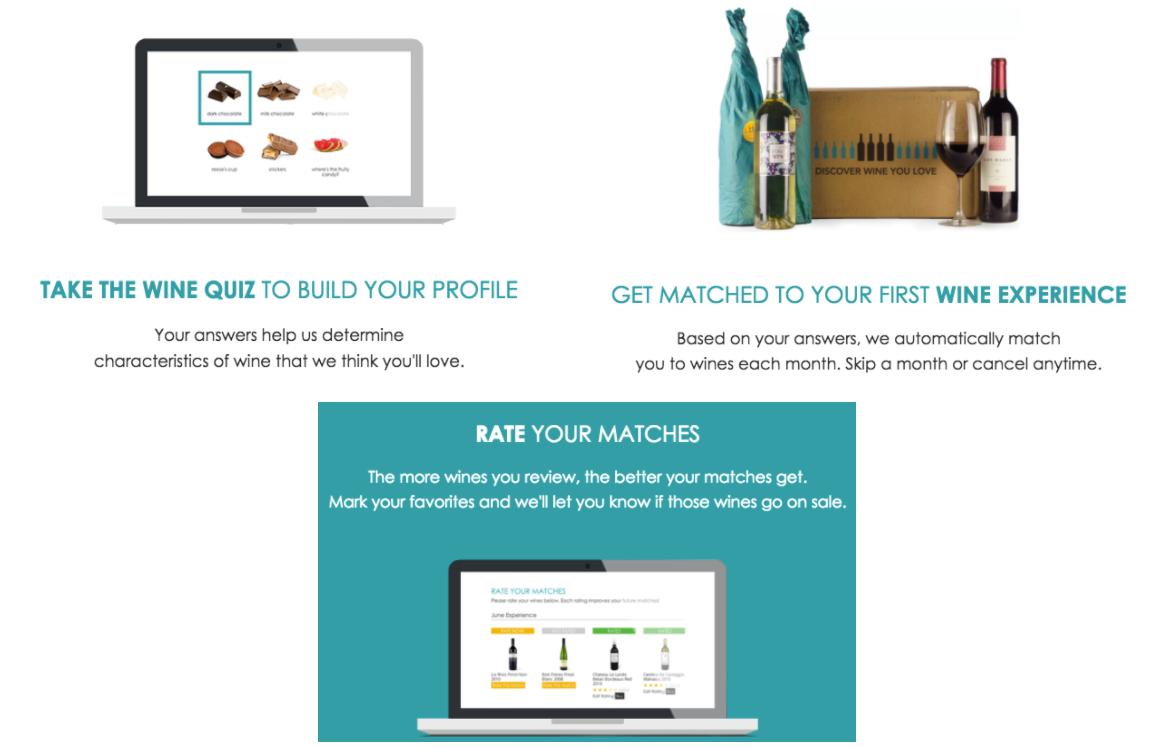
The Company
Yelp! is a platform for user-published reviewers of local businesses. Yelp!’s human users submit feedback to the website on local businesses with two types of information: a 5-star rating and textual reviews.
The Profile
Yelp! is an active user of prize competitions to better understand and use of the human-inputted data and crowdsource novel approaches to improve its service for users. The company is currently promoting the 9th iteration of its dataset challenge, with a total of ten prizes amounting to a modest $5,000.
The subset of data includes 11 cities spanning 4 countries (Germany, UK, US, Canada), which means that users have access to over 4M reviews for ~150K businesses for analysis. For the ninth iteration, Yelp! Is also including 200K user-uploaded photos in the dataset for analysis.
Contrary to the Netflix competition, Yelp! leaves the challenge question and the success metric open-ended to applicants to explore what interests them in the dataset; judging the submissions on technical rigor, the relevance of the results and novelty.
Previous Winners:
One interesting proposal from a winner in the first dataset challenge at University of California-Berkeley used Natural Language Processing (NLP) to extract various subtopics of the individual’s text review. The team used unsupervised machine learning to classify the categories of subtopics that diners mentioned in text reviews; they included areas of interest such as, restaurant service, decor, food quality. With the subcategories developed by the machine algorithm, the team then could predict for a given review what each subtopic’s rating would be.
This form of machine learning and natural language processing is helpful to (1) evaluate the accuracy of the star rating given by a user and (2) help small business owners improve their service. The subtopics approach attempts to not overweight one aspect of a user’s experience into the overall score.
Potential for Improvement
- Yelp! could improve the value of this subtopic analysis with human input. By enabling users to assign tags (“ambiance”, “decor”) to a review or, or even better, a 5-star score for each subtopic (as TripAdvisor currently does), Yelp! could enrich its dataset for users and small businesses. NLP could help suggest tags to users (as with Stack Overflow) from the textual analysis of the provided review or users could input their own.
- One could see this area of subtopics moving in a different direction, as currently, Yelp! reviews are conglomerated for one business that provides multiple services (i.e. a hotel that has a spa and restaurant). Similarly, Yelp! reviews for a restaurant that serves brunch and dinner are combined into a single ratings score. This prohibits users from understanding the value the business provides to them for one particular service. By using NLP and human input on subtopics (e.g. tagging “spa”, “facial”, “brunch”), the user could have a more granular view of the quality of business offering for what the user is trying to achieve. The user could then assess the value of the business based on the service most relevant to their needs, rather than the business as an undifferentiated whole.
https://engineeringblog.yelp.com/2017/01/dataset-round-7-winners-and-announcing-round-9.html
https://www.yelp.com/dataset_challenge
https://www.yelp.com/html/pdf/YelpDatasetChallengeWinner_ImprovingRestaurants.pdf
https://www.ischool.berkeley.edu/news/2013/students-data-analysis-uncovers-hidden-trends-yelp-reviews