Problem
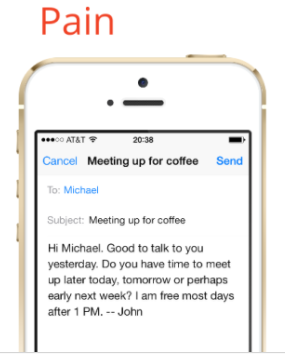
According to The Washington Post [1], on average, you will need to wait 18.5 days before you can get an appointment to see your physician. A lot can happen during 18 days. Eventually, according to the Annals of Family Medicine, 18 percent of patients will decide to skip their appointments during this period because they are [2]:
- Feeling worse and need to go to the emergency room
Overscheduled and forget their appointment - Limited in their healthcare literacy and don’t understand or appreciate why the appointment is necessary
- Not in an established relationship with their doctor and aren’t concerned about missing an appointment
- Influenced by language barriers or, socio-economic factors and misunderstand when their appointment is
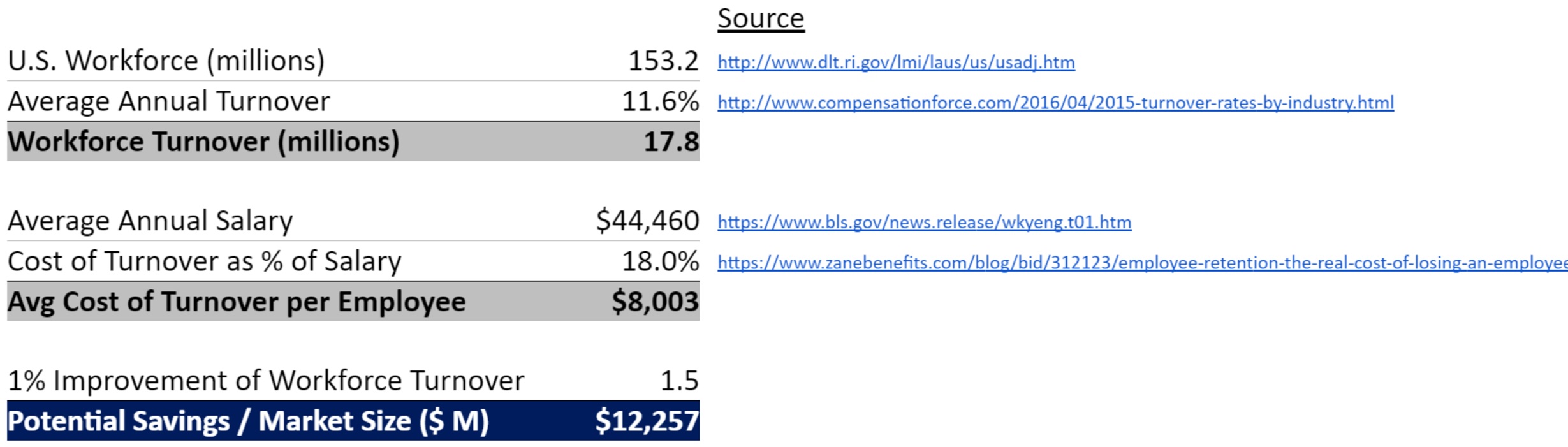
No show’s financial impact on the US healthcare system is estimated as $330+ billion year, resulting in US’s GDP reduction (2% of GDP).
| Example – A doctor is supposed to see 15 patients every day – 10% no-show rate (*1) = 1.5 missed appointments daily = 8 no-shows per week (*2) – The doctor organizes appointments into 30-minute sessions at a cost of $100/session (*3). – Because of the 10% no-show rate, he loses $800 per week. This no-show rate costs the practice around $41,600 per year. – There are approximately 810,000 physicians in the U.S (*4). The total loss is estimated as $337 billion a year (*1) We assumed a conservative 10% no-show rate referring to this study [3] |
Solution
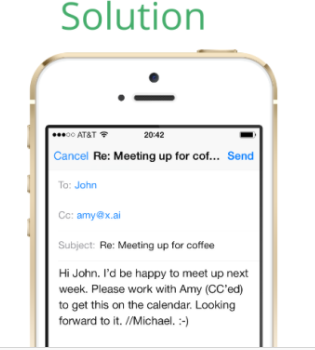
We propose BookMe, a machine learning-based patient management tool (SaaS). With BookMe, medical providers can easily integrate their own website and BookMe Scheduler, which asks patients for an easy sign up and suggests available timeslots based on predicted no-show rates. BookMe also sends automated reminder texts and calls to those with relatively high no-show rates to minimize the costs associated with no show. BookMe predicts no-show rates analyzing a country-wide healthcare data, provider-specific data (if provided), transportation data etc. In addition to this 2-step no-show reduction process, each healthcare provider will get several relevant reports: capacity utilization report and BookMe performance report (prediction power, no-show reduction results, and additional revenue captured by this system).
If a clinic with 10 physicians can reduce no-show rate by 5% (half), it can save $208K a year. Clinics will expect cost cutting of employment through making scheduling and reminder operations automatic. BookMe costs free for small providers (up to 300 reservation a month) and $20/mo for larger providers (300+ reservation a month), both being attached with No-show Reduction Program (text/call reminder service).
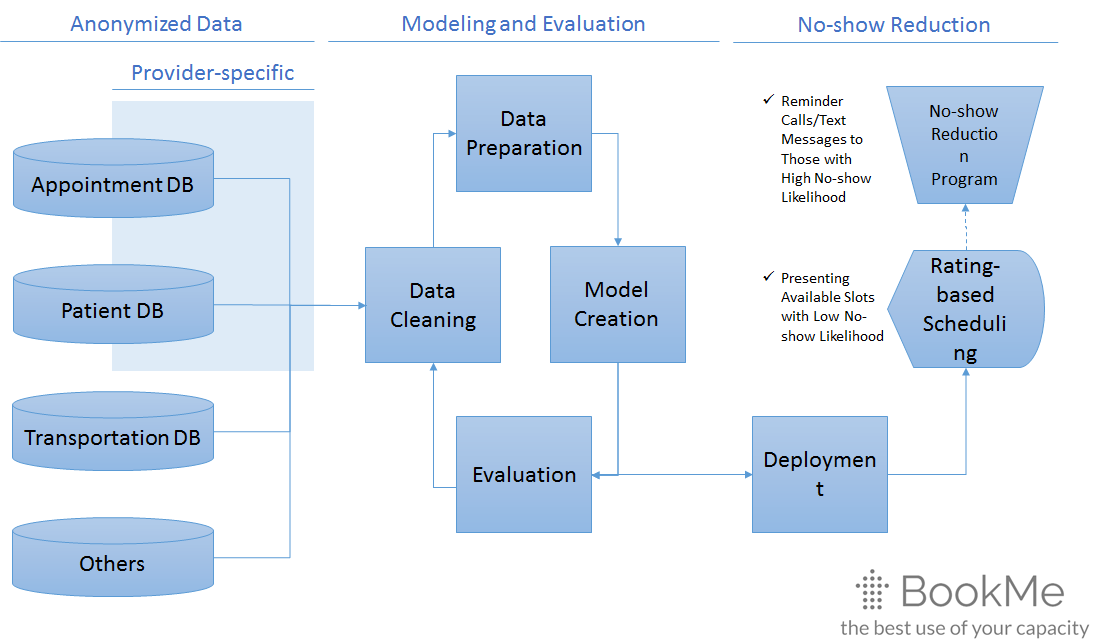
Prototype Development Design
Data Collection
We would collect 10,000+ actual appointment data (gender, age, symptom, phone #, email address, and zip code) from our partner medical centers (University of Chicago and Rush University) through BookMe (beta) in combination with patient personal data (nationality, preferable language, family data, past diagnosis and prescription, etc) the medical centers own. From third party service providers, we would collect transportation data which would be related to one of the factors affecting the decision whether patients should skip their appointments or not. There are some preceding studies [5] about no-show patterns from which we could obtain insights for this process.
Model Development
We will structure Lasso-based logistic regression model with a minimum cross-validation error to predict accurate no-show rate (the higher the worse), which will be repetitively done whenever additional data is imported.
Model Validation
We would review the validation of the future appointment prediction, sorting out multiple reduction factors, in other words, whether the actual reduction comes from 1) optimized slot allocation or 2) no-show reduction program. Additionally, we would study on the effectiveness of adding provider-specific data to sample data because this affects how much data BookMe should collect from providers’ existing database in addition to the patients’ sign up data.
Team members:
Nobuhiro Kawai
Nadia Marston
Lisa Clarke-Wilson
Antonio Salomon
Source: