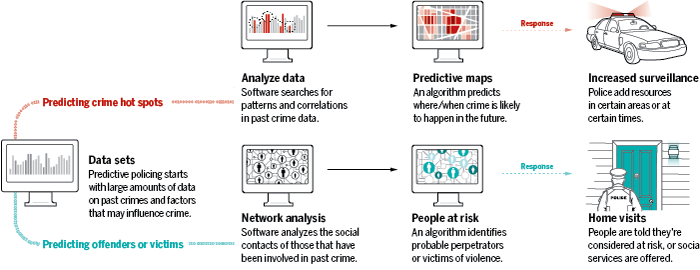
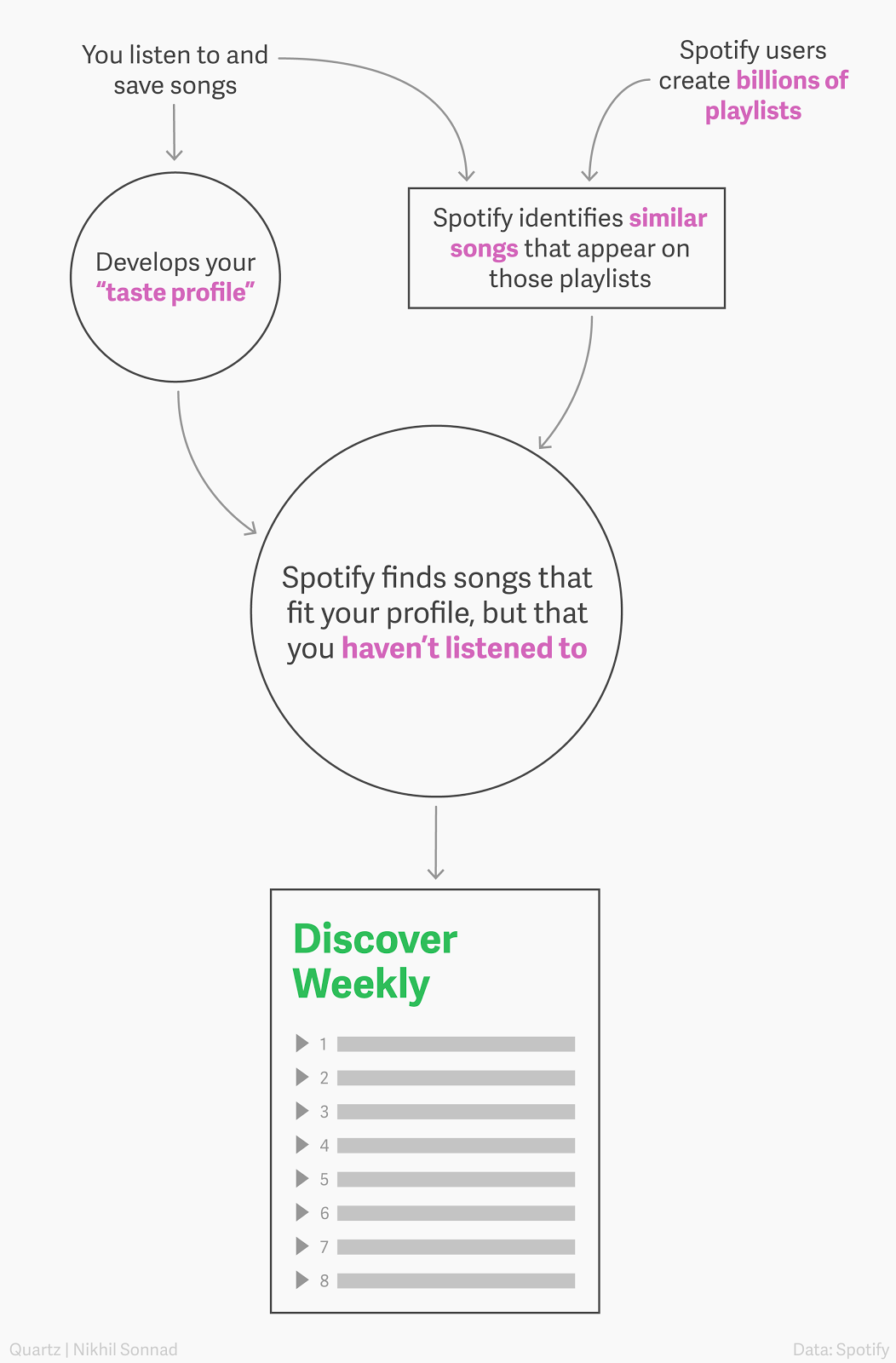
The Problem and the Opportunity
The current college admissions process is flawed. Despite the best efforts of admissions officers to build diverse student classes that have high potential for success, there is little proof to suggest that current application review processes are robust and result in ideal class compositions. A 2006 study by Simonsohn showed that admissions application reviewers weighted the social aspects of an application (e.g., leadership) more heavily than other attributes (i.e. academic factors) on days that were sunny. This worrisome finding demonstrates the outside factors that can affect a human’s judgement and have significant impacts on prospective students’ lives.
A 1996 empirical study conducted by a political scientist at Northwestern University found that the likeliest determinants of admission to college were the standard test scores, grades, and personal information that could be found in one’s application – not the unique, signal characteristics admissions officers claim to look for in essays and interviews that could lead an officer to make a more complete evaluation of the candidate. Perhaps even more worrisome is that admissions offices, outside of those at some of the top universities, do not evaluate the outcomes of application decisions – such as the success of an admitted student or the future financial benefits to the institution of that student’s acceptance – and incorporate that feedback into their admission evaluation criteria.
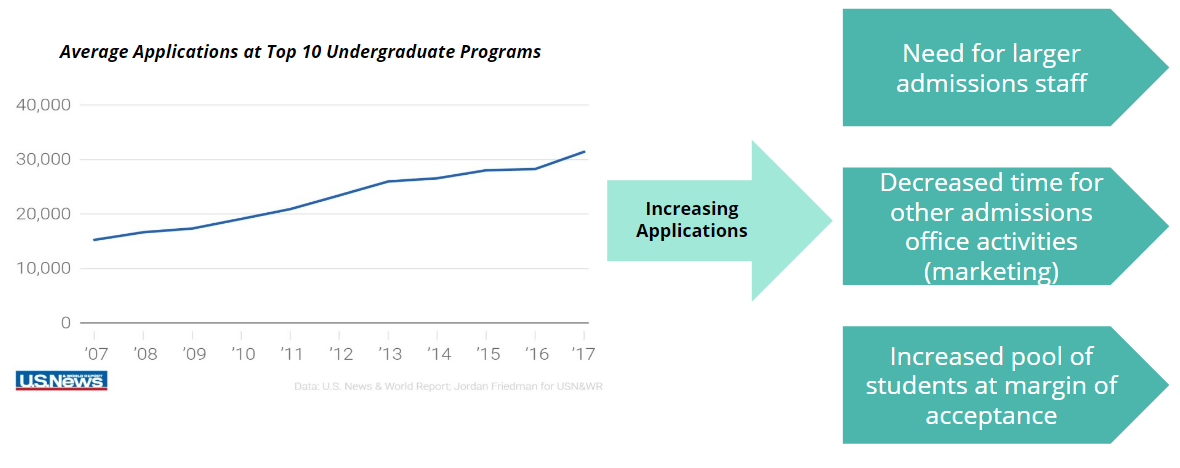
In addition, the application review process at most universities is still largely manual, requiring admissions officers to read, evaluate, and discuss tens of thousands of applications multiple times each year. The significant time spent on even the most clear-cut of cases (either acceptances or denials) . In a University of Texas study of how a machine learning solution could aid PhD application review processes, it was observed that reviewers spent over 700 hours reviewing a pool of 200 applicants. Now, consider that many of the top universities receive tens of thousands of applicants.
Therefore, we see a clear opportunity for a machine learning-based solution to address the existing flaws in the college admissions process. Not only is there a large capturable market with over 3,000 institutions of higher education in the U.S. that all face this admissions evaluation issue, the number of college applications continues to increase, which will only exacerbate the issues described above.
 Our platform, HiPo!, will help provide significant time and human resource savings to university admissions offices. In addition, it will be trained using historical application and student performance data to help admission officers optimize their admissions evaluation process across a number of outcome-based factors (e.g., future earnings potential, yield likelihood, philanthropic giving potential).
Our platform, HiPo!, will help provide significant time and human resource savings to university admissions offices. In addition, it will be trained using historical application and student performance data to help admission officers optimize their admissions evaluation process across a number of outcome-based factors (e.g., future earnings potential, yield likelihood, philanthropic giving potential).
The Solution
The proprietary algorithm will utilize a semi-supervised machine learning model. The supervised elements that the model will optimize for are the quantifiable outcomes such as future earnings potential, yield likelihood, and philanthropic giving potential. However, given the vast expanse of data that the model will be trained on through years of qualitative data from student essays and interview transcripts, there are other elements that, in an unsupervised way, the algorithm can make associations and clusters from to derive additional predictive value. These elements are not as measurable such as creativity or diversity of thought – both things that an admissions committee would value in a class. However, over time if the algorithm can add additional measurable information to admissions officers on these dimensions, they would provide additional evaluative data.
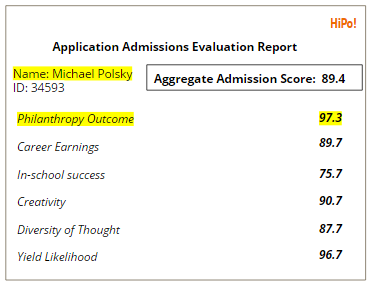
The inputs into the core product are traditional quantitative metrics, such as GPA, standardized testing scores, etc., in addition to qualitative inputs such as essays, interview transcripts, recommendations, and resumes. HiPo! recognizes that each institution may have a different idealized student profile, and these may even vary across different types of programs at that institution (e.g., law school vs. business school vs. undergrad). By creating a robust feedback loop by measuring the success of various students over time based on the HiPo! evaluation criteria, the algorithm will be able to estimate outcomes and provide admissions officers with quantifiable score reports:
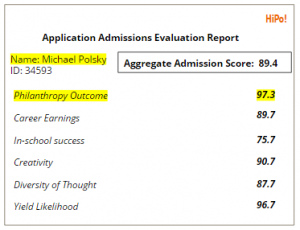 This is merely a prediction of the relative likelihood of future outcomes based on historical results of similar profiled candidates (out of 100), not a pure measure of an individual’s current attributes.
This is merely a prediction of the relative likelihood of future outcomes based on historical results of similar profiled candidates (out of 100), not a pure measure of an individual’s current attributes.
Empirical Demonstration
To validate the effectiveness of the machine learning algorithm and to validate the hypothesis that certain characteristics and patterns present in an candidate’s application, essays, and interviews are reflective of future outcomes, the HiPo! team would perform a demonstration pilot by partnering with an institution of higher education, such as the University of Chicago Booth School of Business. HiPo! would collect historical applicant records from 1950-1992. 75% of this data would be randomly selected to train the algorithm, under the supervised and unsupervised learning methods described above. The algorithm would then be applied to the remaining set of the data. The predictive output of the solution would be measured against actual outcomes of the students evaluated in the sample. For instance, if Michael Polsky MBA ‘87 was evaluated as part of the sample, a successful algorithm would predict that he would have both high career earnings potential and strong likelihood of philanthropic behavior.
Following this initial demonstration, HiPo! Will undergo a more substantial pilot with multiple institutions, focused on optimizing the algorithm for one specific academic program (e.g., MBA) and the ability to “flex” parameters in its algorithm based on institutions’ desires. With highly competitive MBA programs constantly measuring themselves against one another while jockeying for rankings and admitted students, hitting specific metrics (e.g., yield) and demonstrating students’ program-driven success is critical. During the pilot, HiPo! will work with each involved university on the types of class profiles the school hopes to optimize for in its admissions process; one institution may hold social impact as a core component of its mission, while others may want a stronger profile of entrepreneurship. Increasing the repository of data from diverse unbiased sources will even further strengthen the algorithm’s predictive ability to even further tailor the solution to individual clients.
Risks and Mitigants
There could be push back from universities who are concerned that its applicants will be able to “game the algorithm” by using targeted keywords and language in essays to increase the likelihood of recommendation by the engine. However, we assume institutions will operate in their best interests to keep their algorithm highly confidential, preventing this from ever becoming a risk in the first place. In addition, this is easily mitigated through continuous learning and updating of the algorithm. In fact, many students are already attempting to “game the system” in their essays anyway through targeted language throughout their application to catch the eye of admissions staff.
Finally, we see a potential risk with institutions ignoring the mission of HiPo! as a complementary tool to assist admissions staff, and instead relying exclusively on it to make admissions decisions. We strongly discourage completely removing the human element from the decision process.
Funding Request
To build the platform that will be used for the demonstration pilot described above, HiPo! is seeking a $200,000 investment that will be used to hire technical development staff. This number is based on the anticipated salary needs for 2-3 full-stack developers and machine learning experts for a period of 6 months. We anticipate also using these funds to prototype our data management system that will be used to house both historical and customer data that will serve as inputs into the machine learning algorithm.
Sources
Cole, Jonathan R. “Why Elite-College Admissions Need an Overhaul.” The Atlantic. Atlantic Media Company, 14 Feb. 2016. Web. 13 Apr. 2017.
Estrada-Worthington, Rebecca, et. al. “2016 Application Trends Survey Report”. Graduate Management Admissions Council. 2016. Web. 1 May 2017.
Fast Facts. N.p., n.d. Web. 13 Apr. 2017.
Friedman, Jordan. “Explore College Admission Trends at Top National Universities”. U.S. News. 22 Sept 2016. Web. 13 Apr. 2017.
Miikkulainen, Risto, Waters, Austin. “GRADE: Machine Learning Support for Graduate Admissions.” Proceedings of the 25th Conference on Innovative Applications of Artificial Intelligence, 2013.
Simonsohn, Uri. “Clouds Make Nerds Look Good: Field Evidence of the Impact of Incidental Factors on Decision Making.” SSRN Electronic Journal (n.d.): n. pag. 2006. Web. Apr. 2017.